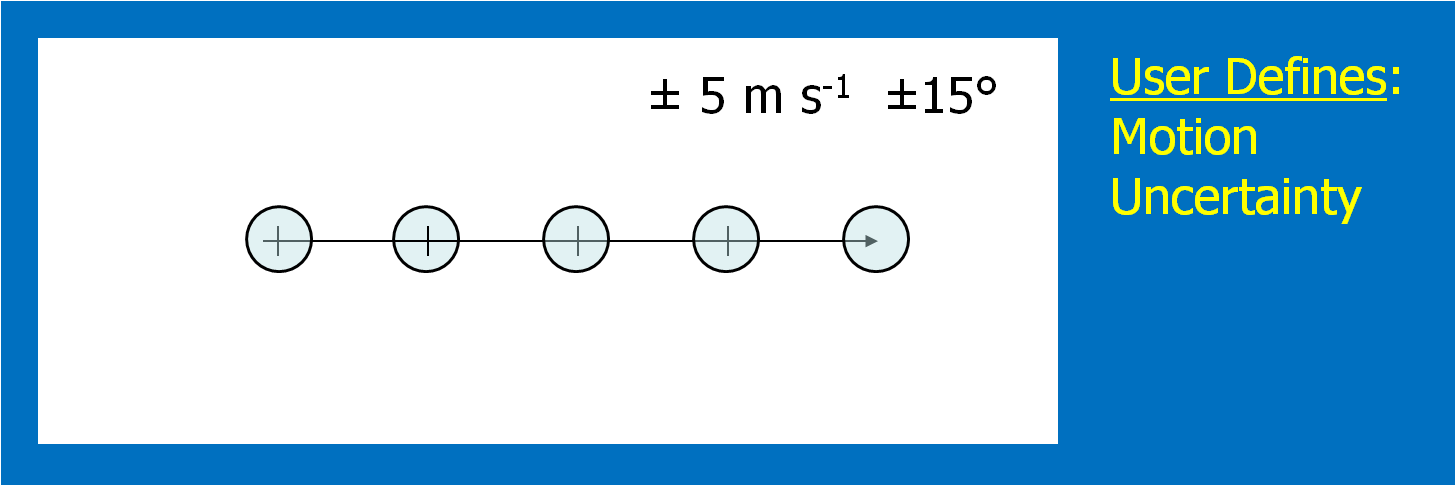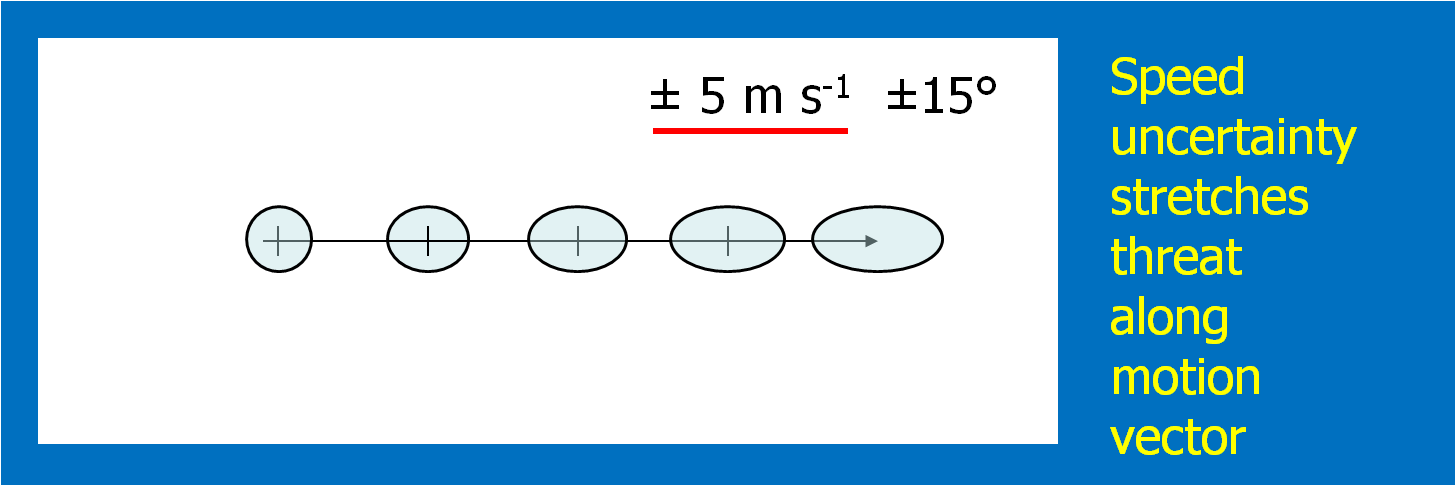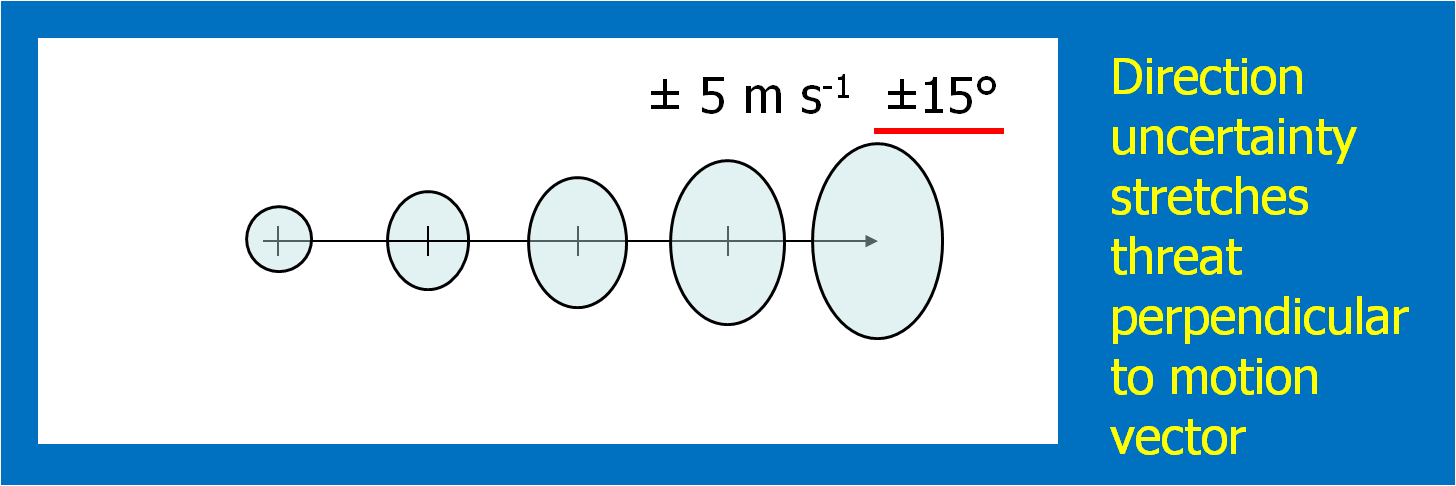An official website of the United States government
Here’s how you know
Official websites use .gov A
.gov website belongs to an official government
organization in the United States.
Secure .gov websites use HTTPS A
lock (
) or https:// means you’ve safely connected to
the .gov website. Share sensitive information only on official,
secure websites.
The information in the PDF manuscript summarizes a lot of the content in this blog. It also includes new work to apply the verification scheme to severe weather warning-scale Probabilistic Hazard Information (PHI). These thoughts will be expanded upon in the blog in the near future.
Since a blog presents stories in reverse chronological order, those new coming into the blog will find my most recent stories first, even though they are intended to be later chapters. So, here is a chronological table of contents of the Experimental Warning Thoughts. I’ll update this and bump it to the top every once in a while.
As finally promised as an “aside” in this blog entry, I will cover the issue of how using point observations can lead to a misrepresentation of the lead time of a warning.
Consider that one warning is issued, and a single severe weather report is received for that warning. We have a POD = 1 (one report is warning, zero are unwarned), and an FAR = 0 (one warning is verified, zero warnings are false). Nice!
How do we compute the lead time for this warning? Presently, this is done by simply subtracting the warning issuance time from the time of the first report on the storm. From this earlier blog post:
twarningBegins = time that the warning begins
twarningEnds= time that the warning ends
tobsBegins = time that the observation begins
tobsEnds= time that the observation ends
LEAD TIME (lt): tobsBegins – twarningBegins [HIT events only]
For ease of illustration, I’m using the spatial scale to represent the time scale. The warning begins at some time twarningBegins, and the report is at a later time tobsBegins. The lead time is shown spatially in the figure, and in this case, it appears that the warning was issued with some appreciable lead time before the event at the reporting location occurs.
However, as we explained in the previous blog post, reports only represent a single sample of the severe weather event in space in time. How can we be certain that the report above represents the location and time of the very first instance that the storm became severe? In all but probably rare cases, it does not, and the storm became severe at some time prior to the time of that report. This tells us that for pretty much every warning (hail and wind events at least), the computed lead times are erroneously too large! Reality looks more like this:
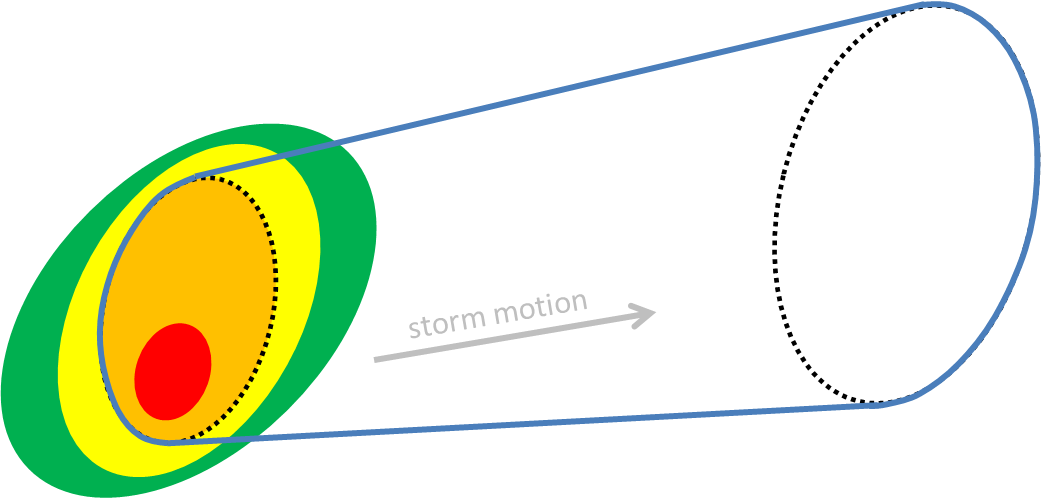
ADDENDUM (1/10/2013): Here is another way to view this so that the timeline of events is better illustrated. In this next example, a warning is issued at t=0 minutes on a storm that is not yet severe, but expected to become severe in the next 10-20 minutes, hence hopefully providing that amount of lead time. Let’s assume that the red contour in the storm indicates the area over which hail >1″ is falling, and when red appears, the storm is officially severe. As the storm moves east, I’ve “accumulated” the severe hail locations into a hail swath (much like the NSSL Hail Swath algorithm works using multiple-radar/multiple-sensor data). Only two storm reports were received on this storm, one at t=25 minutes after the warning was issued, and another at t=35 minutes. That means this warning verified (was not a false alarm), and both reports were warned (two hits, no misses). The lead times for each report were 25 and 35 minutes respectively, but official warning verification uses lead time to the first report known as the initial lead time. Therefore, the lead time recorded for this warning would be 25 minutes, which is very respectable. However, in this case, the storm was actually severe starting at t=10 minutes. The lead time between the start of the warning and the start of severe weather was 15 minutes shorter than that officially recorded.
How can we be more certain of the actual lead times of our warnings? By either gathering more reports on the storm (which isn’t always entirely feasible, although that may be improving with new weather crowdsourcing apps like mPING), or using proxy verification based on a combination of remotely-sensed data (like radar data) and actual reports. Again, more on this later…
I’m back after a too-lengthy absence from this blog. I’ve been thinking about some experimental warning issues again lately, and have a few things to add to the blog regarding some more pitfalls of our current warning verification methodology. I hinted on these in past posts, but would like to expand upon them.
Have you ever been amazed that some especially noteworthy severe weather days can produce record numbers of storm reports? Let’s take this day for example, 1 July 2012:
Wow! A whopping 522 wind reports and 212 hail reports. That must have been an exceptionally-bad severe weather day. (It actually was the day of the big Ohio Valley to East Coast derecho from last July, a very impactful event).
But what makes a storm report? Somebody calls in, or uses some kind of software (e.g., Spotter Network), to report that the winds were X mph or the hail was Y inches in diameter from some location and at some time from within the severe thunderstorm. But the severe weather event is actually impacting an area surrounding the location from which the report was generated, and has been and will occur over the time interval representing the lifetime of the storm. It is highly unlikely that a hail report represented only a single stone falling at that location, or that the wind report represented a single wind gust local to that single location, and there were no other severe wind gusts anywhere else nor at any other time during the storm. Each of these reports represent only a single sample of an event that covers a two-dimensional space over a time period.
If you recall from this blog entry, the official Probability Of Detection (POD) is computed to be the number of reports that were within warning polygons over the total number of reports (inside and outside polygons). It’s easy to see that to effectively improve a office’s overall POD for a time period (e.g., one year), they only need to increase the number of reports that are covered by the warning polygons issued by that office during that time period. One way to do this is to cast a wide net, and issue larger and longer-duration warning polygons. But another way to artificially improve POD is to simply increase the number of reports within storms via aggressive report gathering. Let’s consider a severe weather event like this one:
Look at all those (presumably) severe-sized hail stones. We can make a report on each one, at each time they fell. After about an hour of counting and collecting (before they all melted), this observer found 5,462 hail stones that were greater than 1″ in diameter. Beautiful – the Probability Of Detection is going to go way up! We can also count all the damaged trees as well to add hundreds of wind reports. Do you see the problem here? Are you getting tired of my extrapolations to infinity? Yes, there are literally an infinite number of severe weather reports that can be gleaned from this event (technically, there is a finite number of severe-size hail stones fell in this storm, but who’s really counting that gigantic number?). But let’s scale this back. Here’s a scenario in which a particular warning is verified two different ways:
Each warning polygon verifies, so no false alarms. For the scenario on the top, there is one hit added to all reports for the time period (maybe a year’s worth of warning), but for the bottom scenario, there are seven hits added to the statistics.
But wait, doesn’t the NWS Verification Branch filter storm reports that are in close proximity in space and time when computing warning statistics? Wouldn’t those seven hits be reduced to a smaller amount? They use a filter of 10 miles and 15 minutes to avoid my hypothetical over-reporting scenario. But that really doesn’t address the issue entirely. One can still try to fill every 10 mile and 15 minute window with a hail or wind report in order to maximize their POD. But if you think about it, that’s not really a bad idea. In essence, you are filling a grid with a 10 mile and 15 minute resolution with as much information known about the storm as possible. But this works only if you also call into every 10-miles/15-minute grid point inside and outside every storm. Forecasters rarely do this (and realistically can’t), because of workload issues, and because only one report within a warning polygon is all that is needed to avoid that warning from being labelled a false alarm (again, cast the wide net so that one can increase their chance of getting a report within the warning).
CORRECTION (1/10/2013): I just learned that the 10 mile / 15 minute filtering was only done in the era of county-based warning verification, and is not done for storm-based verification. Therefore, my arguments against the current verification methodology where hit rates and POD can be stacked by gathering more storm reports is further bolstered. More information is in the NWS Directive on forecast and warning verification.
If we knew exactly what was happening within the storm at all times and locations at every grid point (in our case, every 1 km and 1 minute), we’d have a very robust verification grid to use for the geospatial warning verification methodology. But we really don’t know exactly what’s is happening everywhere all the time because it is nearly impossible to collect all those data points. The Severe Hazards Analysis and Verification Experiment (SHAVE) is attempting to improve on the report density in time and space. But their resources are also finite, and they don’t have the staffing to call into every thunderstorm. Their high-resolution data set is very useful, but limited to only the storms they’ve called. What could we do to broaden the report database so that we have a better idea of the full scope of the impact of every storm? One concept is proxy verification, in which some other remotely-sensed method is used to make a reasonable approximation of the coverage of severe weather within a storm, like so:
This set of verification data will have a degree of uncertainty associated with it, but the probability of the event isn’t zero, and is thus, useful. It is also very amenable to the geospatial verification methodology already introduced in this blog series. More on this later…
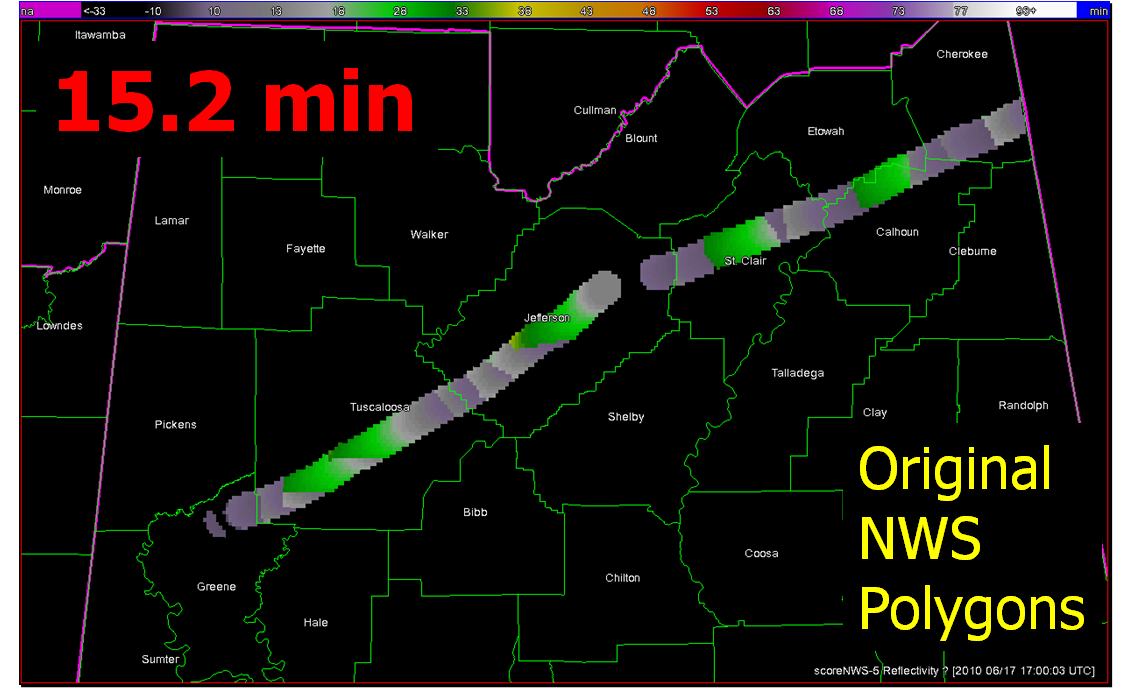
For my presentation at the 2011 NWA Annual Meeting in Birmingham, I wanted to introduce the concept of geospatial warning verification and then apply it to a new warning methodology, namely Threats-In-Motion (TIM). To best illustrate the concept of TIM, I’ve been using the scenario of a long-track isolated storm. To run some verification numbers, I needed a real life case, so I chose the Tuscaloosa-Birmingham Alabama long-track tornadic supercell from 27 April 2011 (hereafter, the “TCL storm”), shown in earlier blog posts, and I’ll repeat some of the figures and statistics for comparison. This storm produced two long-tracked tornadoes within Birmingham’s County Warning Area (CWA).
The choice of that storm is not meant to be controversial. After all, the local WFO did a tremendous job with warning operations, given the tools and they had and within the confines of NWS warning policy and directives. Recall the statistics from the NWS Performance Management site:
Probability Of Detection = 1.00
False Alarm Ratio = 0.00
Critical Success Index = 1.00
Percent Event Warned = 0.99
Average Lead Time = 22.1 minutes
These numbers are all well-above the national average. We then compared these numbers to those found using the geospatial verification methodology for “truth events”:
CSI = 0.1971
HSS = 0.2933
Average Lead Time (lt) = 22.9 minutes
Average Departure Time (dt) = 15.2 minutes
Average False Time (ft) = 39.8 minutes
And recall the animation of the NWS warnings I provided in an earlier blog post:
What if we were to apply the Threats-In-Motion (TIM) technique to this event? Recall from this blog entry that I had developed a system that could automatically place the default WarnGen polygons at the locations of human-generated mesocyclone centroids starting at the same minute that the WFO issued its first Tornado Warning on the storm as it was entering Alabama. I used a re-warning interval of 60 minutes. If you adjust the re-warning interval to one minute (the same temporal resolution of the verification grids), you now have a polygon that moves with the threat, or TIM. The animation:
Let’s look at the verification numbers for the TIM warnings:
CSI = 0.2345
HSS = 0.3493
Average Lead Time (lt) = 51.2 minutes
Average Departure Time (dt) = 0.8 minutes
Average False Time (ft) = 23.1 minutes
Comparing the values between the NWS warnings and the TIM warnings visually on a bar graph:
All of these numbers point to a remarkable improvement using the Threats-In-Motion concept of translating the warning polygons with the storm, a truly storm-based warning paradigm. Let’s also take a look at how these values are distributed in several ways. First, let’s examine Lead Time. The average values for all grid points impacted by the tornado (plus the 5 km “splat”) are more than doubled for the TIM warnings. How are these values distributed on a histogram:
For the TIM polygons, there are a lot more values of Lead Time above 40 minutes. How do these compare geospatially?
Note that the sharp discontinuities of Lead Time (from nearly zero minutes to over 40 minutes) at the downstream edges of the NWS warnings (indicated by yellow arrows in the top figure) are virtually eliminated with the TIM warnings. You do see a few discontinuities with TIM; these small differences are caused by changes in the storm motions at those warned times.
Moving on to Departure Time, the average values for all grid points impacted by the tornado (plus the 5 km “splat”) are reduced to nearly zero for the TIM warnings. How are these values distributed on a histogram:
And geospatially:
With the TIM polygons, the departure times across the path length of both tornadoes is pretty much less than 3 minutes everywhere. Whereas, the NWS polygon Departure Times are much greater, and there are some areas still under the NWS warning more than 30 minutes after the threat had passed.
Finally, looking at False Alarm Time distributions both on histograms and geospatially:
There are some pretty large areas within the NWS polygons that are under false alarm for over 50 minutes at a time, even though these warnings verified “perfectly”. In comparison, the TIM warnings have a much smaller average false alarm times for areas outside the tornado path (about a 42% reduction). However, there are a number of grid points that are affected by the moving polygons for just a few minutes. How would we communicate a warning that is issued and then canceled just a few minutes later? That is food for future thought. I’ve also calculated an additional metric, the False Alarm Area (FAA), the number of grid points (1 km2) that were warned falsely. Comparing the two:
NWS FAA = 10,304 km2
TIM FAA = 8,103 km2
There is a 21% reduction in false alarm area with the TIM warnings, much less than the reduction in false alarm time. The reduction in false alarm area is more a function in the size of the warning polygons. The WarnGen defaults were used for our TIM polygons, but it appears that the NWS polygons were made a little larger than the defaults.
So, for this one spectacular long-tracked isolated supercell case, the TIM method shows tremendous improvement in many areas. But there are still some unanswered questions:
How will we deal with storm clusters, mergers, splits, lines, etc.?
How could TIM be implemented into the warning forecaster’s workload?
How would the information from a “TIM” warning be communicated to users?
How will we deal “edge” locations under warning for only a few minutes?
Here I’m going to describe the “Threats-In-Motion”, or TIM concept that was presented at the 2011 National Weather Association Annual meeting. Essentially, once a digital warning grid is created using the methodology presented in the previous blog entry, the integrated swath product would start to translate automatically. The result would be that the leading edge of the polygon would inch downstream, and the trailing edge would automatically clear from areas behind the threat. We hypothesize that this would result in a larger average lead time for users downstream, which is desired. In addition, the departure time of the warning should approach zero, which is also considered ideal. The concept is first illustrated with a single isolated long-tracked storm for ease of understanding. Later, I will tackle how this will work with multi-cell storms, line storms, and storms in weak steering flow.
Why are Threats-In-Motion desired? Let’s look at the way most warning polygons are issued today. Threats that last longer than the duration of their first warning polygon will require a subsequent warning(s). Typically, the new warning polygon is issued as the current threat approaches the downstream end of its present polygon or when the present polygon is nearing expiration. This loop illustrates this effect on users at two locations, A and B. Note that only User A is covered by the first warning polygon (#1), even though its location is pretty close to User B’s location. Note too that User A gets a lot of lead time, about 45 minutes in this scenario. When the subsequent warning polygon (#2) is issued, User B is finally warned. However, User B’s lead time is only a few minutes, much less than User A who may only live a few miles away.
What if a storm changes direction or speed. how are the warnings handled today. Warning polygon areas can be updated via a Severe Weather Statement (SVS), in which new information is conveyed and the polygon might be re-shaped to reflect the updated threat area. This practice is typically used to remove areas from where the threat already passed, thus decreasing departure time. However, NWS protocol disallows the addition of new areas to already-existing warnings. So, if a threat areas moves out its original polygon area, the only recourse is to issue a new warning, sometimes before the original warning has expired. You can see that in this scenario:
Note that a 3rd polygon is probably required at the end of the above loop too!
In the past entry, I introduced the notion of initial and intermediate forecasted threat areas. The forecasted areas can update rapidly (one-minute intervals), and the integration of all the forecast areas results in the polygon swath that we are familiar with today’s warnings. But, there is now underlying (digital) data that can be used to provide additional specific information for users. I will treat these in later blogs:
Meaningful time-of-arrival (TOA) and time-of-departure (TOD) information for each specific location downstream within the swath of the current threat.
Using the current positions of the forecasted threat areas to compare to actual data at any time to support warning operations management
But what about “Threats-In-Motion” or TIM? Here goes…
Instead of issuing warning polygons piecemeal, one after another, which leads to inequitable lead and departure times for all locations downstream of the warning, we propose a methodology where the polygon continuously moves with the threat. Our scenario would now look like this:
Note that User A and User B get equitable lead time. Also note that the warning area is cleared out continuously behind the threat areas with time. And here is the TIM concept illustrated on the storm that right turned.
Now let’s test the hypotheses stated at the beginning of this entry. Does TIM improve the lead time and the departure time for all points downstream of the threat? If yes, what about the other verification scores introduced with the geospatial verification system, like POD, FAR, and CSI? The next blog entry will explore that.
We will now introduce a new approach to creating convective weather hazard information which was first tested at the NOAA Hazardous Weather Testbed (HWT) with visiting NWS forecasters in 2007 and 2008. The new warning methodology varies in complexity and flexibility, but we will first present the basic concepts first. In this approach, the forecaster still determines a motion vector and chooses a warning duration. However, instead of tracking points and lines, the forecaster outlines the probable severe weather threat area at the current time, and inputs motion uncertainty. From this information are derived high-resolution rapidly-updating geospatial digital hazard grids. These grids are used to generate a wide variety of useful warning information, including warning swaths over a time period, meaningful information for time of arrival and departure for any location within the warned area, and probabilistic information based on the storm motion uncertainty.
First, let’s tackle the subject of this entry, “let’s get digital”. Right now, the official warning products are still transmitted as an ASCII text product, and all the pertinent numerical information in the warning like begin and end times, polygon lat/lon coordinates, and other information needs to be “parsed” out of the text product in order for various applications to take advantage of them (e.g., iNWS mobile alerting). This is an archaic method to deliver information, especially in this day and age of digital technology. Various options are being explored to improve the data delivery method, including encoding the warning information into the Common Alerting Protocol (CAP) format. While we feel this is an improvement, it is not going to be sufficient to completely convey all the possible modes of hazard information that can be created and delivered. For example, the polygon information is still encoded as a series of lat/lon points within the CAP formatted files. But what if the polygon is comprised of complex boundaries or curved edges? Or what if we want to include intermediate threat area information at specific times steps during the warning? Considering that we’ve made the argument for gridded warning verification, we feel that hazard information should be presented as a digital grid, more easily exploitable by today’s technology. You’ll understand why in a little bit…
So first addressing how a forecaster determines a current threat, instead of choosing points or lines and trying to decide where to place these points within the storm hazard areas, we feel that the warnings should be based on the tracking of a threat area. Here are the proposed steps in this new warning process. For each step, I’ve also added a snippet of ideas for “more sophistication” that I may explore further in later blog entries.
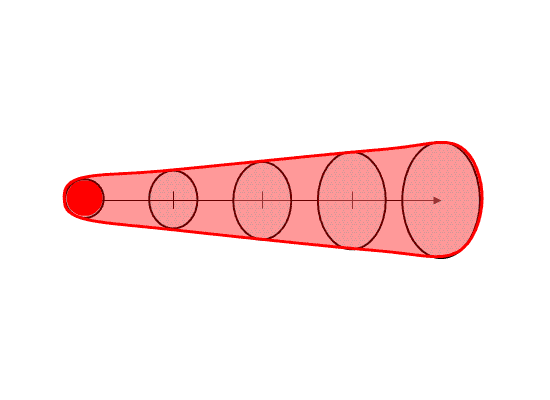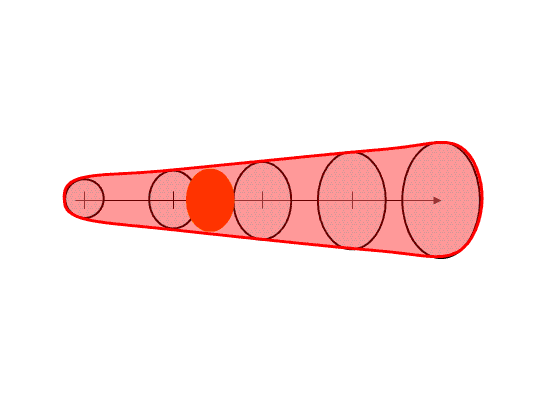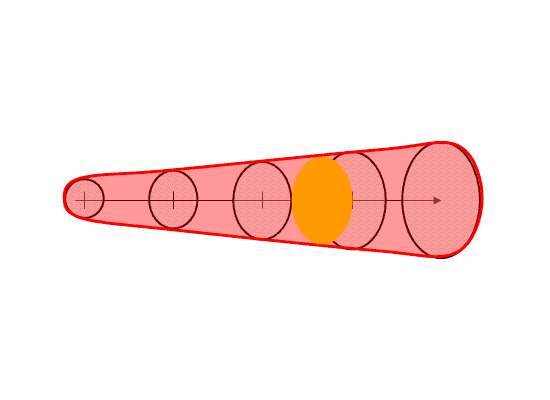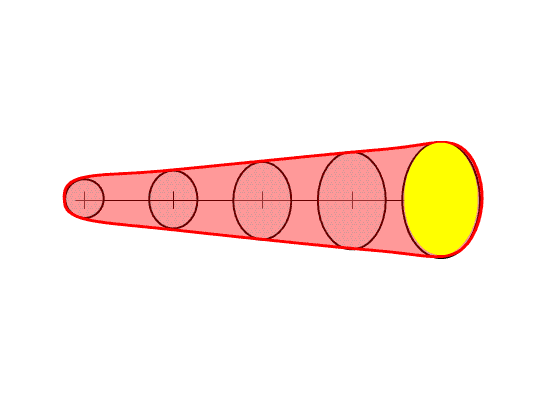
1. The forecaster outlines the current threat area.
For our HWT exercises, we gave the forecaster two options, a) draw a free-hand multi-sided polygon, or b) fit the current threat area with and ellipse. (The latter was offered because it is easier to project an area described by a known mathematical function, than it is for a free-hand polygon area). Where is the threat outline drawn? That is currently up to the forecaster to make their best determination where the severe weather currently resides in the storm. They can make use of radar and other data as well as algorithms for their decisions. Fig. 1 illustrates an initial threat area defined as a circular area. A circle is chosen to illustrate the effect of some of the later concepts below.
[More sophistication: The threat area is currently a deterministic contour (inside = yes or 100%, outside = no or 0%), but because we are entering data digitally, this initial threat area could be a probabilistic grid. For now, to keep it simple, we’ll just go with “you’re either in or you’re out”.]
Figure 1.
2. Determine the threat motion vector.
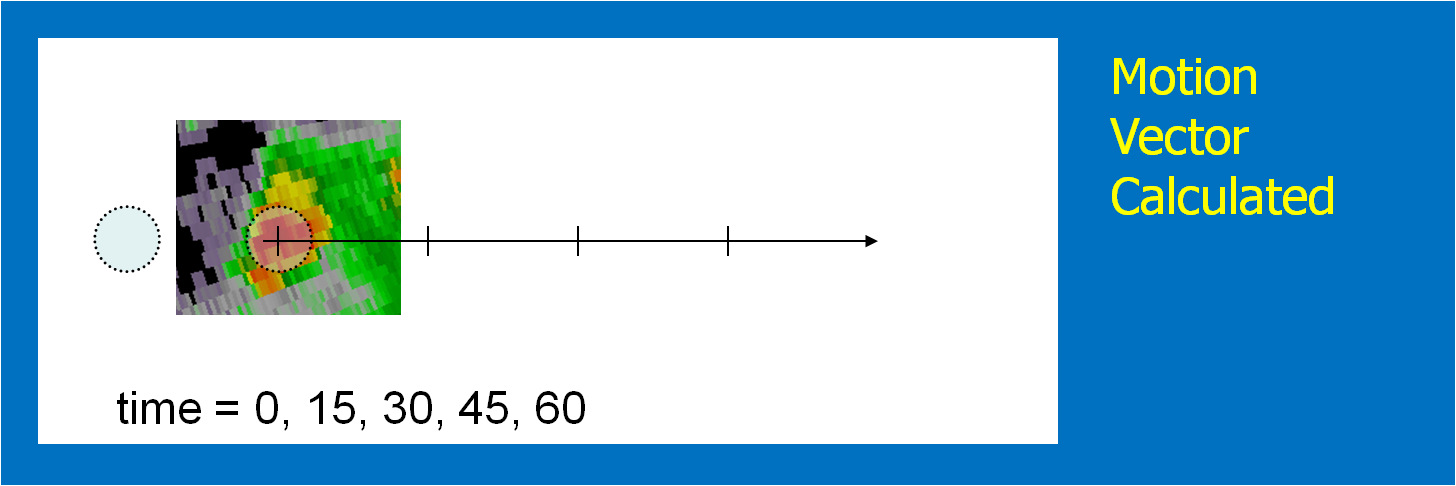
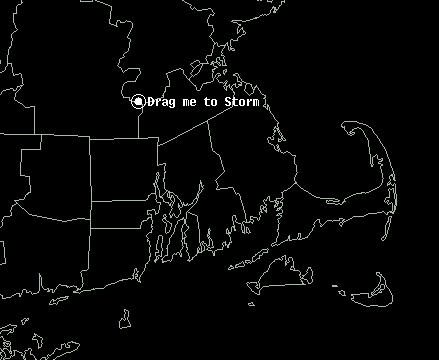
The motion vector could be determined using today’s WarnGen method of “Drag Me To Storm”. This is done by finding a representative location in the storm to track on the current radar volume scan, and then stepping back to a past volume scan (Fig. 2; 20 minutes in the past) and dragging the point to the same feature (Fig. 3). The distance and orientation between the current and past points would define the motion vector (Fig. 4). This is how we did it during our HWT exercises.
[More sophistication: Determine the motion vector by stepping the radar data back in time and repeating the process in step 1, drawing another threat hazard area. Then, an application such as the K-Means segmentation algorithm developed by NSSL could determine the motion vector betwen the two threat areas, or even a high-resolution two-dimensional motion field.]
Figure 2.Figure 3.Figure 4.
3. Choose a warning duration.
This is usually easy – how long does the forecaster want the warning to extend. The initial threat area is then projected to the final position. In addition, the threat area is projected to every time step between the warning issuance time and the warning duration time. We used a time interval of one minute in the HWT experiment. Figure 5 shows the projected threat area at 15-minute intervals; the intermediate intervals are not shown. Remember this aspect of the methodology! It has great implications, which I will explain soon.
[More sophistication: Typically, Severe Thunderstorm Warnings and Tornado Warnings rarely exceed 60 minutes, even if the forecaster is tracking a well-defined long-tracked supercell that has a high certainty of surviving past 60 minutes – simply due to NWS warning protocol. The warning duration could be “indefinite” until the hazard information blends upscale with information from nowcasts and forecasts. How? We’ll get to that later.]
Figure. 5
4. Determine the uncertainty of the motion estimate.
This could be approached in a number of different ways. For the HWT experiments, the forecasters simply chose a range of symmetric speed and direction offsets. For example, ±30° and ±5 kts. Although we didn’t offer this choice during the 2007-8 HWT experiments, the offsets could be asymmetric (e.g., + 30°, -10°, +5 kts, -8 kts). Fig. 6 shows an example offset for motion uncertainty. Figs. 7 and 8 show how speed and direction uncertainty (respectively) affect the shape of the translating initial threat area in time. Speed (direction) uncertainty stretches the initial threat area parallel (perpendicular) to the motion vector.
Once the above four quantities have been chosen by the forecaster, we can then generate a downstream “swath” that will be affected by the translating threat area. The swath is simply the total integration of all of the one-minute interval translating threat areas during the duration of the warning (Fig. 9).
Figure 9.
Here’s a better way to visualize the above static figure. Figure 10 shows a loop of the translating threat area over the forecast interval. The moving threat areas, integrated over the duration of the warning, providing the swath.
Figure 10.
Note that the resulting “polygon” is exactly tied to the parameters of the warning as determined by the forecaster. The resulting integrated polygon cannot (and should not) be editable. The forecaster can only control the shape and position of the swath by changing the input parameters used to create the swath in order to ensure those values are always correlated with the integrated downstream swath.
The base digital grids that can be created in this process are the current threat area and the forecasted one minute translating threat areas out to the duration of the warning. For our HWT experiments, we used a resolution of 1 km2, which is the same resolution I employ within my geospatial warning verification methodology. The forecasted one-minute interval threat grids can be used to create time-of-arrival and time-of-departure grids as well, which given the motion uncertainty information, can be expressed as a range of times (the range interval would decrease as the threat grew closer). In addition, the integrated swath can also be saved as a digital grid. The swath product can also be contoured to provide a series of lat/lon points that are analogous to today’s polygon warnings. Metadata can also be added to the grids in the form of qualitative descriptions of the event, much like what is added to the WarnGen template output (e.g., “A TORNADO WITH DEBRIS WAS REPORTED AT HWY 9 AND JENKINS”).
The above four items were all that were required to create our digital hazard grids for the 2007-2008 HWT experiments. How does this compare to the way forecasters issue warnings today using AWIPS WarnGen software?
A current threat area is drawn, versus a point or line.
Motion uncertainty is added.
That’s not much more than is currently input from the forecaster today. Although it is slightly more information and workload, there are numerous benefits to this technique, which will be tackled in the next blog entry.
This concept isn’t the only way a current threat area can be forecasted. In this methodology, the threat area expands based on forecaster input of motion uncertainty. However, the uncertainty could also be based upon statistical analyses a la Dance et al. (2010; a Gaussian model). Or, as we begin to approach the Warn-On-Forecast era, the extrapolated downstream threat areas might be enhanced by ensemble numerical model output to allow for discrete propagation, cell mergers, splits, growth, decay, and any other types of non-linear evolution of convective hazards. The concepts presented here will form the framework for these future improvements.
WarnGen limits the user to only one default choice for the initial or projected threat areas. The same parameters (10km, 15km) are always used. Of course, the meteorologist can actually change these areas by manually editing the default polygon points. The back end of the warning can be edited to conform to the shape of the current threat area. The front end of the warning can also be edited to conform to the projected future shape of the warning area. But recall that once you start to edit the points in the polygon, you have now decoupled the motion vector and duration from the warning. In fact, the point position and motion vector happen to be transmitted in the warning text. When the forward portions of the warning are changed without adjusting the motion vector and/or duration of the warning, it becomes possible for a sophisticated user to project the current position based on the motion vector and discover that the forecast future position may not even lie within the warning polygon swath. Confusion could reign!
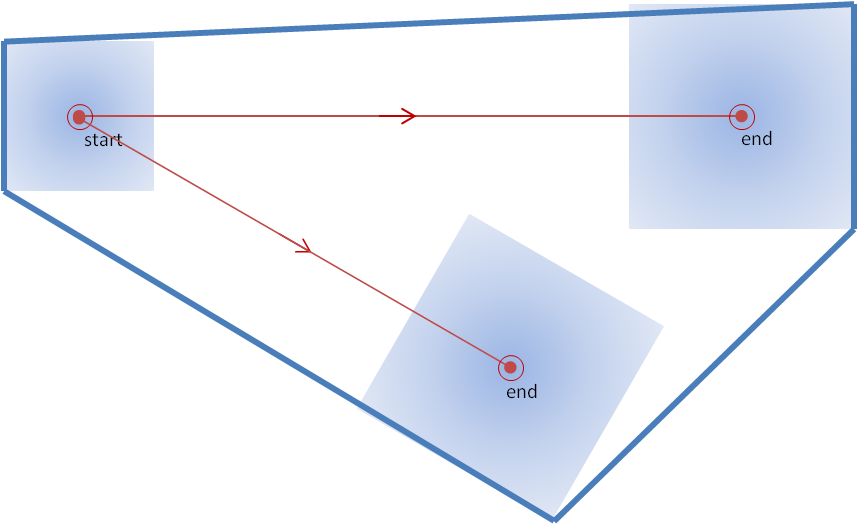
What about the placement of the point or line? Where should these go? Let’s just look at the point placement, the “Drag Me To Storm” position.
This point is used to represent the “storm”. But does this get placed at the centroid of the storm (option 1)? Or is it placed on the leading edge of the storm along the centroid motion vector (option 2)? Or the most forward portion of the echo (option 3)? Or elsewhere? This point is used to project the future location of the threat at the end of the warning, and also to compute the “pathcast” information. But if the point doesn’t actually represent the full spatial extent of the threat, wouldn’t the resulting polygons and pathcasts be incorrect? For example, if using the centroid of the storm, the severe weather might commence before reaching the centroid of the storm, and the polygons and pathcasts would be lag in time.
So let’s say for example we track using the storm centroid. Without editing the default polygon, you can see that a portion of the storm threat might be missed using the default box sizes. One could manually edit the polygon, but this would be done entirely qualitatively. How could this be done quantitatively?
In either case, the storm hazard isn’t a point, but it is a two-dimensional area. In a way, WarnGen provides a 2D threat area, but it is a perfect square 20 km on each side. No storm actually has those dimensions. It therefore makes more sense that we should be defining 2D threat areas, and projecting 2D threat areas at future positions, like so (assuming the orange contour represents the spatial extent of the severe weather in this storm):
In addition, the future threat area defaults to a set expansion rate (exactly 150% its original size), and there is no direct way for the forecaster to quantify how much the threat area will expand, or how the projected area should be modulated to account for motion uncertainty or storm evolution.
We’ll show you one method in which we can address these shortcomings of WarnGen next, a proposed method for creating the short-fused convective hazard grids that does a better job at quantifying and directly coupling current and projected threat areas, motion, and motion uncertainty. In addition, this new warning generation methodology can provide intermediate threat area locations within the entire swath of the warning, plus one other major benefit: Threats-In-Motion (TIM), to be described very soon in this blog.
This is the first step in a proposed new hazard information delivery methodology that we feel will naturally dovetail toward the future “Warn-On-Forecast” paradigm of using numerical ensemble guidance to predict storm evolution beyond simple detection and extrapolation of threats.
Let’s address the second and third shortcomings of WarnGen, (b) There is no way to adjust the motion vector for uncertainty. This must be done as a guess by manually editing the polygon vertices; (c) There is no way to change the default choice for the initial or projected threat areas. The same parameters (10km, 15km) are always used, and a square area is always the default.
In WarnGen, the forecaster can only choose one motion vector, and is limited to only one expression of uncertainty in the motion – the increase in the size of the warning area to a square with an area 225% larger than the initial threat area square. What if the forecaster determines that the storm is moving into an environment that is supportive of an evolution to a supercell, and the storm slows its forward speed and turns to the right (increasing azimuth in the motion vector)? The practice that is typically being suggested is to edit the vertices of the polygon to include more area to the right of the motion vector:
But how does the forecaster determine how far to the right to re-position the vertex? It’s another guess! Just click the vertex, drag it until it “looks about right”.
What would be the more robust way to determine how far to stretch the polygon? By being able to input information about the motion uncertainty in the form of a possible variance in the motion vector. For example, if the forecaster thinks a storm has a chance to slow and move to the right of the current motion vector based on the “30R75” technique (30 degrees to the right, 75% of the speed), then that information could be input to determine the possible locations of the threat area at the extrapolated final position of the threat. Here, I’ll only show the default threat position, and the 30R75 threat position:
This looks similar to the “skewed coffin technique” offered by Nietfeld, but in this case, the position of the second solution is based on actual motion uncertainty numbers input by the forecaster, rather than a guess.
This is still not the ideal solution for determining the swath shape based on storm motion vector uncertainties. We’ll get to that soon.
In the next set of blog entries, you are going to hear a lot more opinion and ideas of where some of us in the National Weather Center (NWC) community in Norman think we can begin to exploit technology to improve the way the NWS delivers hazardous convective weather information to its customers. It should be noted that these ideas are still in the process of being vetted across many disciplines: meteorology, technology, social science, ergonomics, etc. It has been a challenging process, namely because the resources to carry this out have been hard to come by. But we have been able to exhibit some of these ideas to NWS forecasters via the NOAA Hazardous Weather Testbed (HWT) and a social science stakeholder workshop and gained their valuable feedback. Our overarching goal is to improve the digital communication of hazard information to provide the best decision support services to the entire spectrum of users that the government serves.
So let’s continue by examining some of the shortcomings of the WarnGen function in AWIPS. Bear in mind that these comments are not meant to disparage the excellent work that the developers have done, but to highlight how we can evolve into an improved and more robust system to deliver hazardous weather information. Many of our concepts have been introduced at the first two Integration Hazard Information Systems (IHIS) workshops and are being considered by the GSD developers as the framework for the IHIS software is developed.
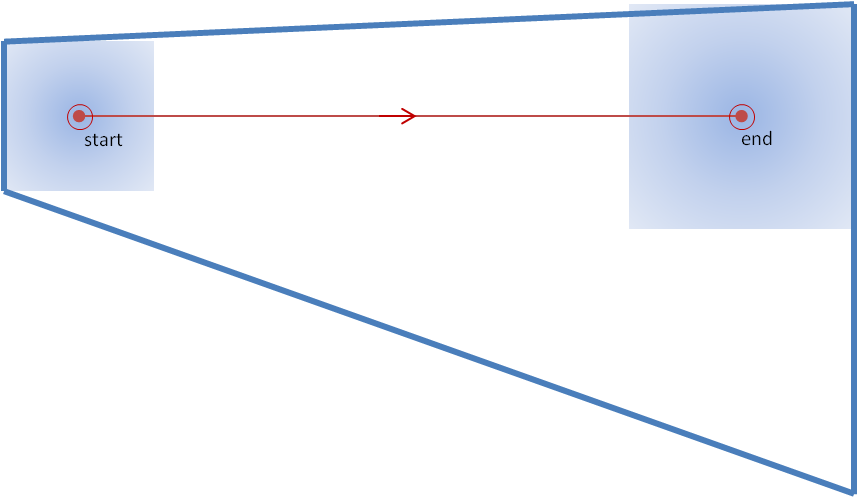
As you recall from earlier blog posts, WarnGen creates its default polygons thus:
1. Forecaster drags a point or line to a location on the storm at the current time
2. Forecaster steps the radar data back in time and drags the point or line to a location on the storm at some past time
3. The distance and bearing between the two points/lines, along with the time difference of the two radar frames, is used to determine a motion vector for that storm.
4. The forecaster selects a warning duration.
5. The point/line is extrapolated to its calculated position based on the motion vector and warning duration.
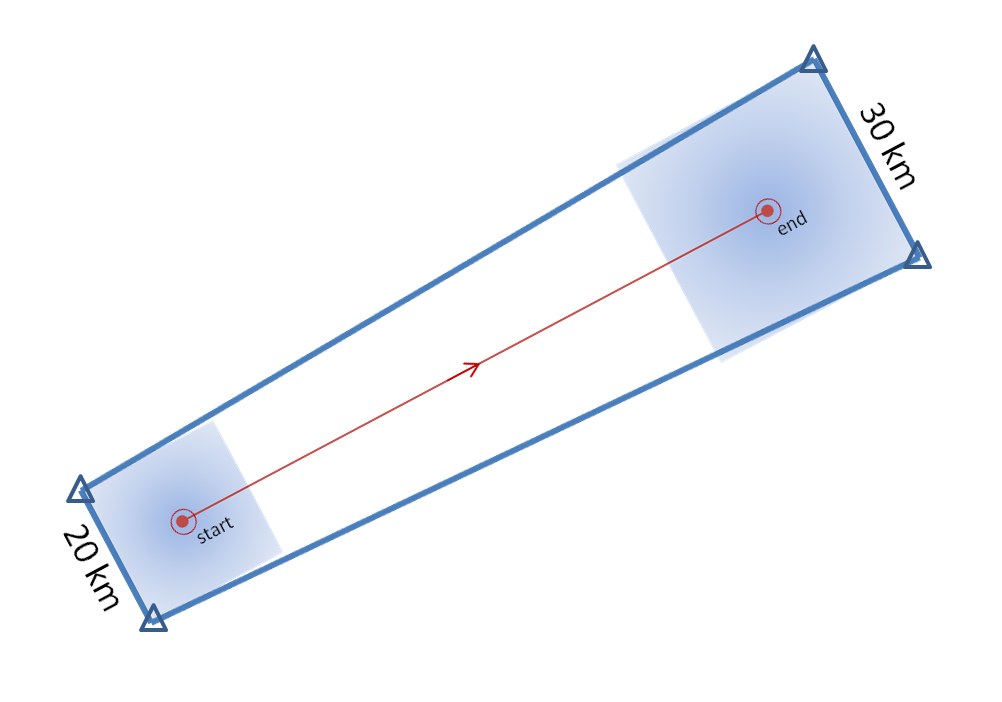
6. Around the initial point/line is drawn a 10 km buffer to represent the current threat area (20 km back side for point warnings).
7. Around the extrapolated point/line is drawn a 15 km buffer to represent the forecast threat area (30 km front side for point warnings).
8. The back corners of the current threat area are connected to the forward corners of the forecast threat area to create default polygon. See here again, for a point-based polygon:
9. This polygon can then be edited by adding, deleting, or modifying any of the vertices (the triangles in the above figure).
10. The warning polygon is transmitted with accompanying text.
Here’s a list of some of the shortcomings to this process:
a. If any of the vertices of the polygon are changed, the polygon is no longer coupled to the motion vector, duration, and the initial and projected threat location.
b. There is no direct way to quantify motion uncertainty. This must be done as a guess by manually editing the polygon vertices.
c. There is no way to change the default choice for the initial or projected threat areas. The same parameters (10km, 15km) are always used.
d. Information about the intermediate threat area locations is not part of the warning. The polygon represents only the swath of the threat swept out through the duration of the warning.
e. If the storm changes its predicted evolution (motion vector, grows, shrinks, splits, etc), there is no way to adjust the polygon swaths without (in most cases) having to issue another polygon to account for the change.
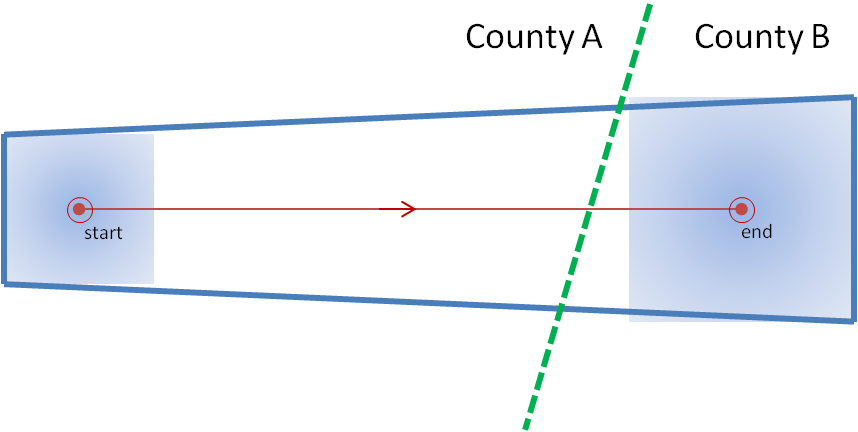
Let me first address limitation (a). Let’s take a look at a situation that we’ve observed a number of times with warnings, and is actually taught as a “best practice”. A warning polygon is issued that covers two counties. The downstream end of the polygon extends not too far into the next county. The warning forecaster does not have enough confidence that the storm will remain severe into the end of that county, so the forecaster “clicks off that county” (this can be done within Warngen – counties can be removed or added at the click of a mouse.) The warning is then transmitted. See anything wrong here?
Let’s look at this in pictures. Here’s the original warning polygon, with the county borders included. Let’s assume that this warning is in effect for 60 minutes:
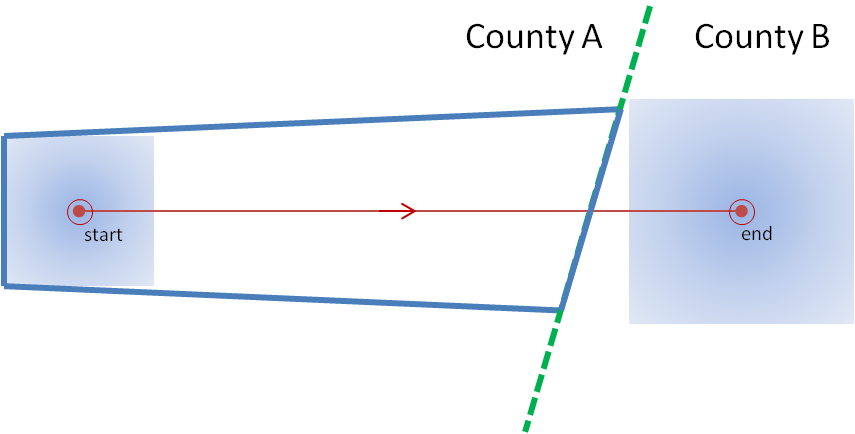
And here is the new warning polygon after County B has been “clicked off”:
I’ve left the background extrapolated threat point and area on the second figure. Note that the warning polygon was edited and then transmitted. An important step was omitted! Assuming that storm moves exactly as extrapolated, where will that storm be in 60 minutes? Located at the end point. When will that warning polygon expire? When the storm is located at the end point. Is the storm inside the polygon? No! The storm exited the polygon well before the polygon expired. If the forecaster was relying on an alerting application (such as SevereClear) to announce that the warning was nearing expiration, the forecaster may get the alert well after the storm as already exited the polygon, and the storm becomes unwarned! The storm escaped its cage and is on the loose!
Some warning forecasters will account for this issue before transmitting the polygon by reducing the duration of the warning. But how is the new duration chosen? How does the forecaster know exactly at what time the storm will be at the end of the shortened warning? They really don’t, and they have take a guess.
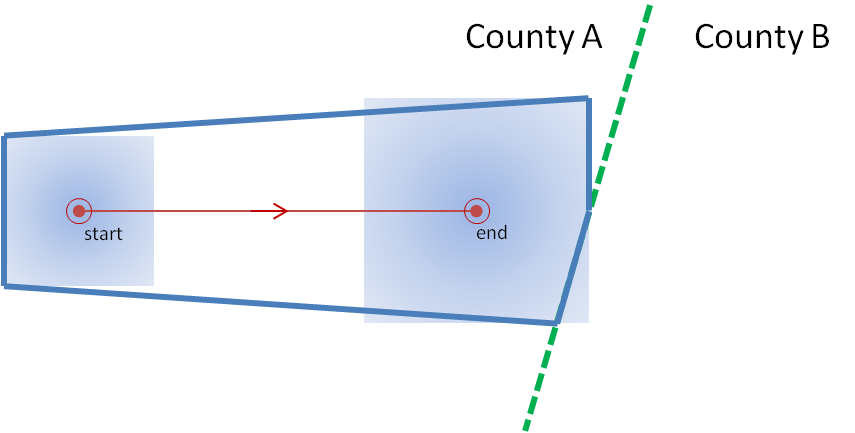
How should the warning be adjusted for uncertainty of duration? Not by editing the polygon, which should represent the accumulated swath of all the extrapolated positions of the threat area from the current time, through all intermediate positions, to the final position. Instead, it should be done by adjusting the duration of the warning, thus affecting the final extrapolated position of the threat. Here’s the same warning with a 40 minute duration (note that even though I slightly clipped the county, I don’t advocate this in the purest sense):
Yes, this can all be done carefully using WarnGen, but we have a better idea how the warnings swaths should be created. This new idea will also address the other shortcomings, which I will describe next.