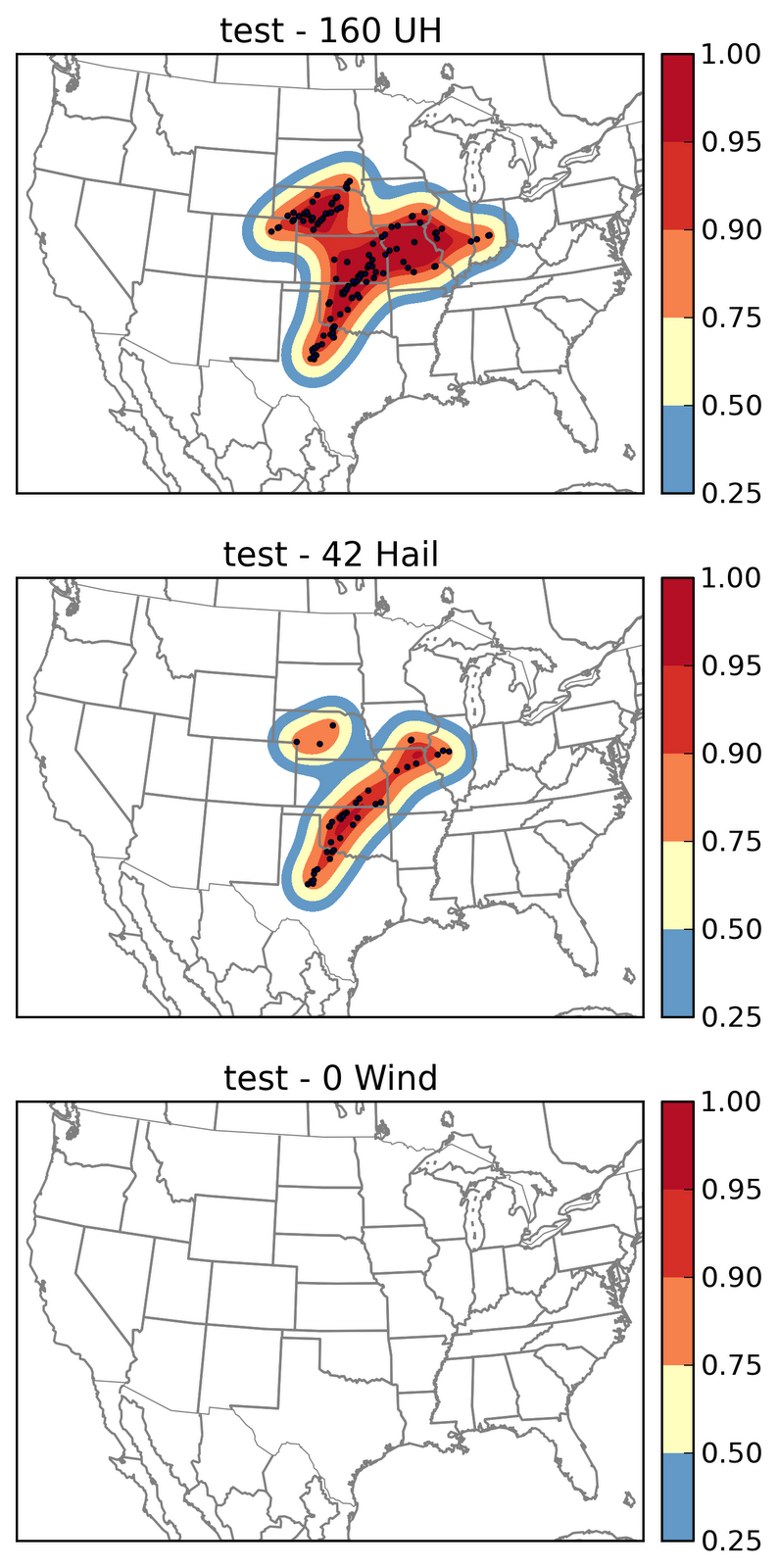
Well, the atmosphere is showing her cards slowly but surely. The big questions this morning were initiation and coverage in OK especially along the dryline. Convection allowing model guidance was flip flopping in every way possible. Lets remind ourselves that this is normal. The models only marginally resolve storms let alone the initiation process.
Given the recent outbreaks, convection allowing models have a hard time predicting supercells, especially when they remain discrete supercells (in the observations). Models have all kinds of filters to get rid of computational noise and it is likely partially this noise that contributes to initiation of small storms. This is speculation but it is a good first guess. The evidence comes from monitoring every time step of the model and seeing how long storms last and the one thing that stands out is that small storms happen in the model, remain small, and are thus short-lived. To be maintained, I argue that they must grow to a scale large enough for the model to fully resolve them.
Back to the uncertainty today. Many 0000 UTC hi-res models were not that robust with the dry line storms. And even at 1200 UTC, not that robust except for 1 or 2. Even the SREF that I saw yesterday via Patrick Marsh’s weather discussion was a potpourri of model solutions dependent on dynamic core.
So now that the dryline appears to be initiating storms the question is how many. Well given the current observations your guess is as good as mine. A slug of moisture (mid to upper 60’s) is sitting in western OK in and around where yesterdays supercells dumped upwards of 2″ of rain, while temps warm into the 80’s. That is going to mean low LCL heights throughout the state. The dryline itself is just east of Liberal, KS and west of Gage, OK. Good clearing now occurring in western OK though there is touch of cirrus still drifting through. Much of the low cloud has cleared and a cumulus field stretches along the dryline down into Lubbock. Clearly the dryline is capable of initiating storms and the abundant moisture /favorable environment/ is not going to be at issue today.