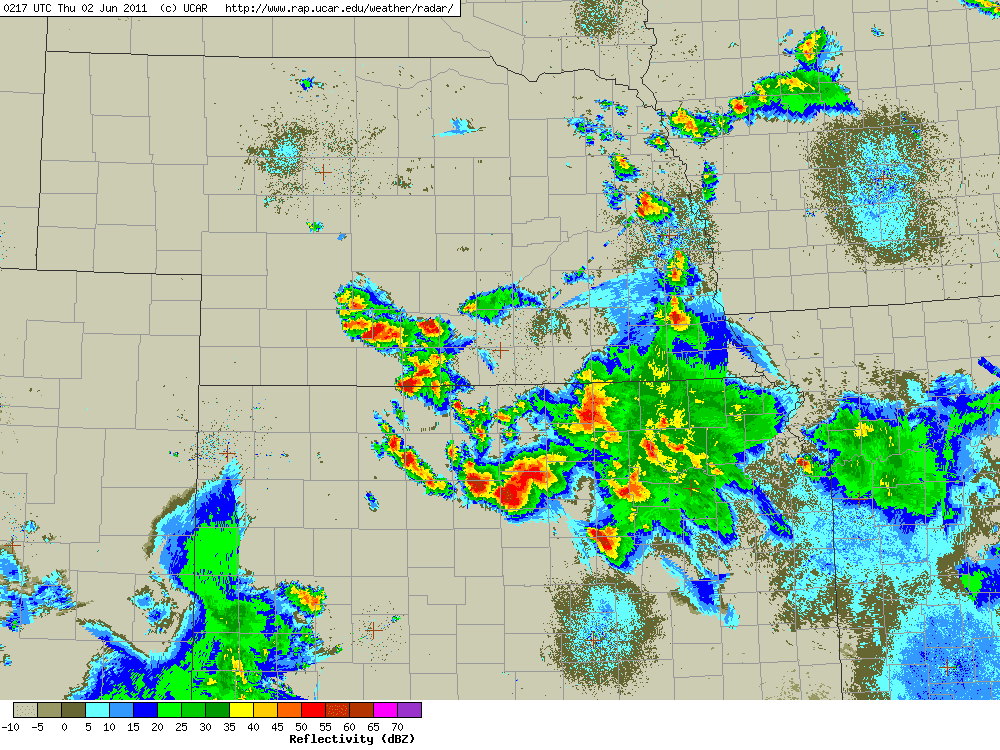
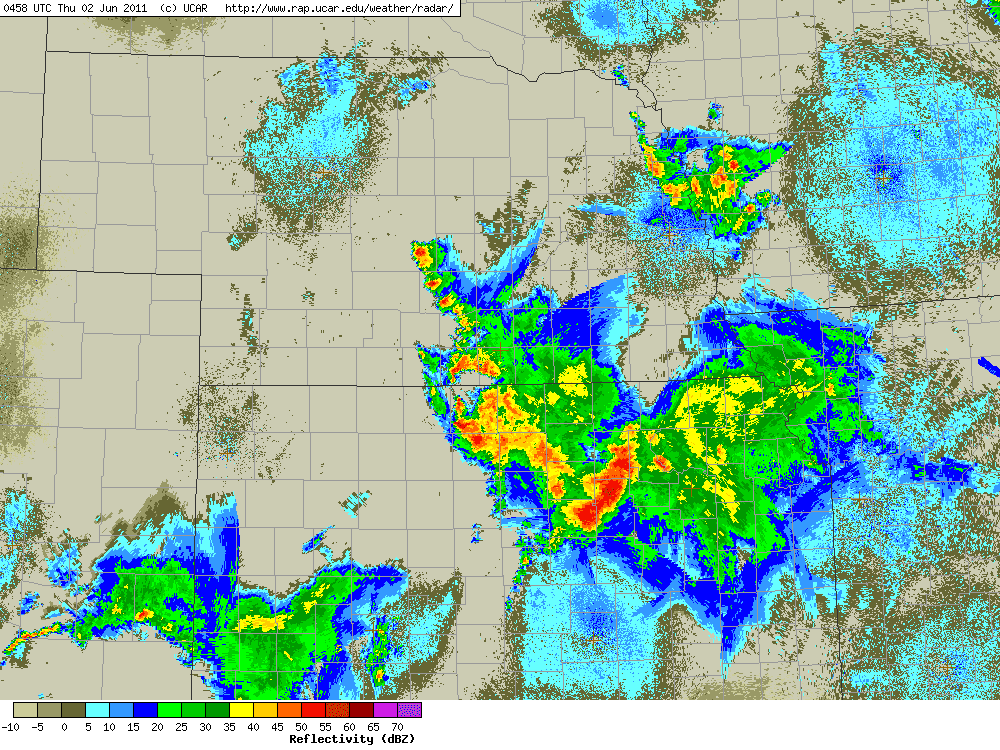
Today’s forecast on CI focused on the area from northeast KS southwest along a front down towards the TX-OK panhandles. It was straightforward enough. How far southwest will the cap break? Will there be enough moisture in the warm sector near the frontal convergence? Will the dryline serve as a focus for CI, given the development of a dry slot present just ahead of the dryline along the southern extent of the front and a transition zone (reduced moisture zone)?
So we went to work mining the members of the ensemble, scrutinizing the deterministic models for surface moisture evolution, examining the convergence fields, and looking at ensemble soundings. The conclusion from the morning was two moderate risk areas: one in northeast KS and another covering the triple point, dryline, and cold front. The afternoon forecast backed off the dryline-triple point given the observed dry slot and the dry sounding from LMN at 1800 UTC.
The other issue was that the dryline area was so dry and the PBL so deep that convective temperature would be reached but with minimal CAPE (10-50 J kg-1). The dry LMN sounding was assumed to be representative of the larger mesoscale environment. This was wrong, as the 00 UTC sounding at LMN indicated an increase in moisture by 6 g/kg aloft and 3 at the surface.
Another aspect to this case was our scrutiny of the boundary layer and the presence of open-cell convection and horizontal convective rolls. We discussed, again, that at 4km grid spacing we are close to resolving these types of features. We are close because of the scale of the rolls (in order to resolve them they need to be larger than 7times the grid spacing) which scales with the boundary layer depth. So a day like today where the PBL is deep, the rolls should be close to resolvable. On the other hand, there is a need for additional diffusion in light wind conditions and when this does not happen, the scale of the rolls collapses to the scale of the grid. In order to believe the model we must take these considerations into account. In order to discount the model, we are unsure what to look for besides indications of “noise” (e.g. features barely resolved on the grid, scales of the rolls being close to 5 times the grid spacing).
The HCRs were present today as per this image from Wichita:
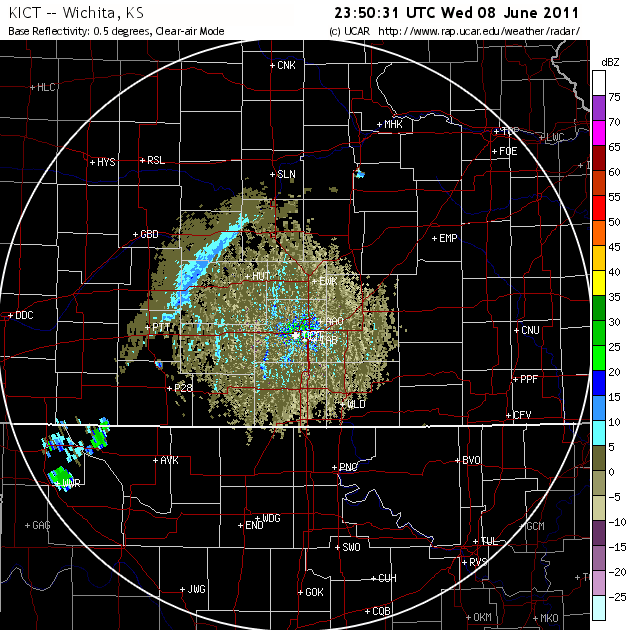
However, just because HCRs were present does not mean I can prove they were instrumental in CI. So when we saw the forecast today for HCRs along the front, and storms developed subsequently, we had some potential evidence. Given the distance from the radar, it may be difficult if not impossible, to prove that HCRs intersected the front, and contributed to CI.
This brings up another major point: In order to really know what happened today we need a lot of observational data. Major field project data. Not just surface data, but soundings, profilers, and low level radar data. On the scale of The Thunderstorm Project, only for numerical weather prediction. How else can we say with any certainty that the features we were using to make our forecast were present and contributing to CI? This is the scope of data collection we would require for months in order to get a sufficient amount of cases to verify the models (state variables and processes such as HCRs). Truly an expensive undertaking, yet one where a number of people could benefit from one data set and the field of NWP could improve tremendously. And lets not forget about forecasters who could benefit from having better models, better understanding, and better tools to help them.
I will update the blog after we verify this case tomorrow morning.