

What can I say. We verified our Tuesday forecasts and felt pretty good capturing the elevated convection over KS and OK at about the right time (1st lightning strike was 45 minutes before our period start time) for an elevated convection event and we rocked it out in CO during the day.
Which brings us to Wednesday. A slight risk in OK with a triple point from a warm front, stationary front and dryline in place. The dryline was forecast to be nice and strong, with horizontal convective rolls (HCRs) present on the north side interacting with the dryline circulation, and more HCRs in the dry air behind the dry line further south. The end result was a series of CI failures (indicated exclusively by accumulated precipitation) along the dryline, but eventually classic right moving supercells (1 or 2 dominant and long lived) were present in the ensemble. The HCRs were detected via some of the unique output variables we are experimenting with, particularly vertical velocity at 1.1 km AGL.
The complicating factor was that not all members had supercells, perhaps 1 in 3. We also had a situation where CI was very sensitive to the distribution of mixing ratio in the warm sector. It appeared we had two different behaviors along the dryline southward, but a definite moisture pool was dominant to the north. This pool was in the area where the dryline bent back westward and where the HCRs directly interacted with the dryline/warm front boundary. There was very little vertical velocity in the warm sector. Not sure why this was the case, assuming the PBL heights were not much lower than 1.1 km.
But lets be serious. There was not a whole lot of over-forecasting by the models. Storms did attempt to form. They just didn’t last very long or get very strong. Nor could we really call them storms (having met no single definition of CI other than some coherent weak reflectivity). In this case it appears the strongest forcing (the dryline and HCRs) was separated from where the realizable instability was present. We analyzed where, when, and how the instability could be realized (in great detail) in the model. We could not verify these models with observations because we don’t have very many sounding sites nor do we have frequent launches. What we could not do is pinpoint where this forecast was going wrong.
The KOUN sounding is presented below:
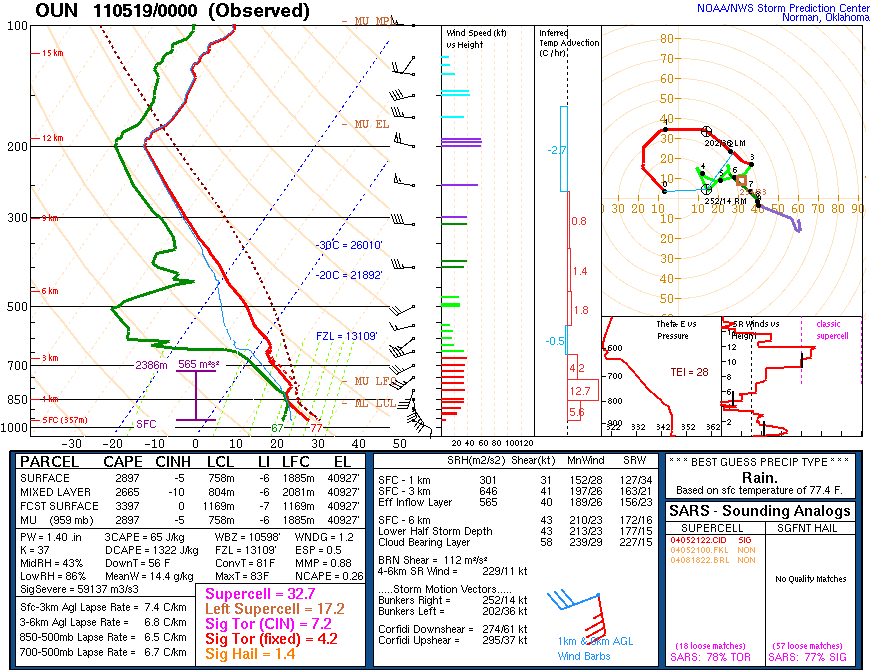
Note that this sounding has nearly 3000 J/kg CAPE with 43 knot deep layer shear, and strong (31 knot) 0-1km shear. An ideal sounding for supercells, and possibly tornadoes. But Norman is well away from where the dryline was setup in western OK. There are no sounding sites in SW OK or NW OK. If we look at LMN which is north of OUN and happens to be north of the warm front:
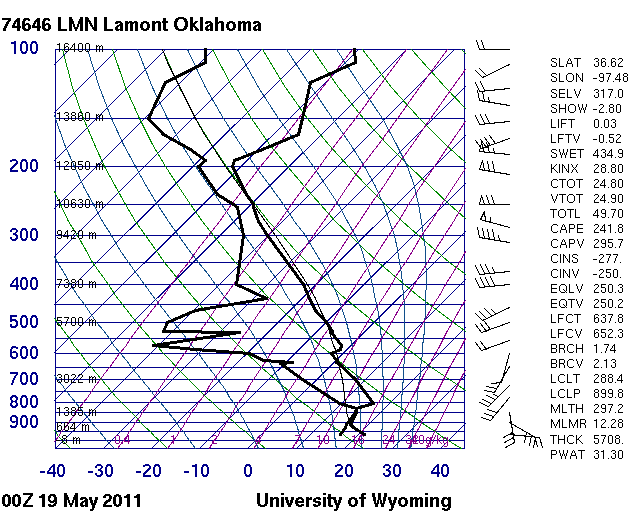
We see very little instability because of cooler surface temperature and dew point and an elevated capped layer. Modifying this sounding for surface conditions at OUN would indicate strong instability and no cap using the virtual parcel. It is unlikely to be this easy as there is probably some mesoscale variability that has not been sampled in this area.
What is clear is that the forecasters were very much willing to buy into a reasonable solution. What we lacked was a solid reason to not believe the models. I am assuming we should first believe the models and that is perhaps not the best starting point. So lets reverse that thought: what reasons did we use to believe the models? I won’t speak for the group, but we should address this question when we review this event tomorrow.
Another point: Assume the model is not a poor representation of observations. What if it was very close? How could we recognize the potentially small errors which could lead to the development of storms or the lack there of? These are really fundamental questions that still need to be addressed.
On a day like today it would have been highly valuable to have soundings in key storm-scale locations near the dryline in the warm sector to the east, and to the immediate north between the dryline and warm front. At the very least we can ascertain if the model was depicting the stratification correctly and also the moisture content, instability and inhibition. It would have been great to have a fine scale radar to measure the winds around the dryline to look for HCRs.