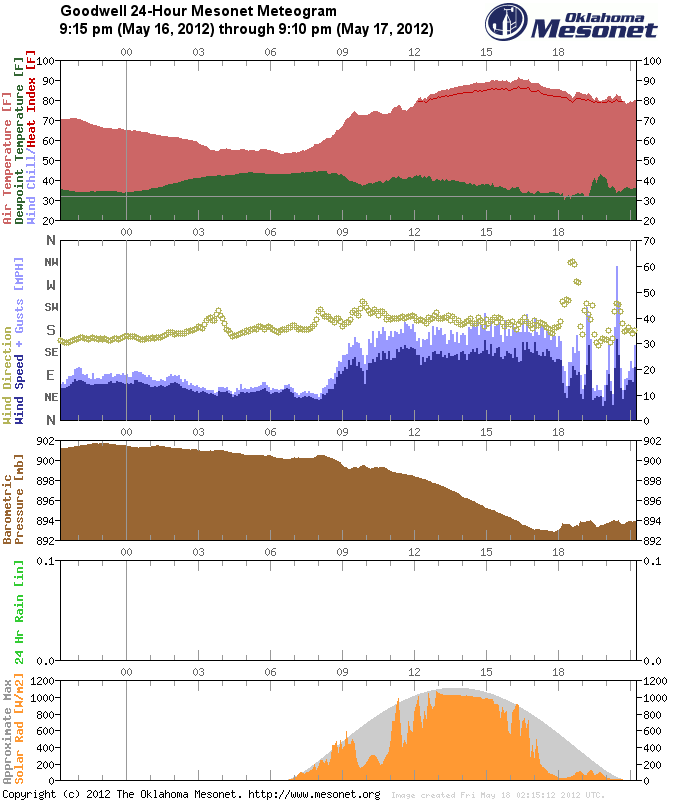
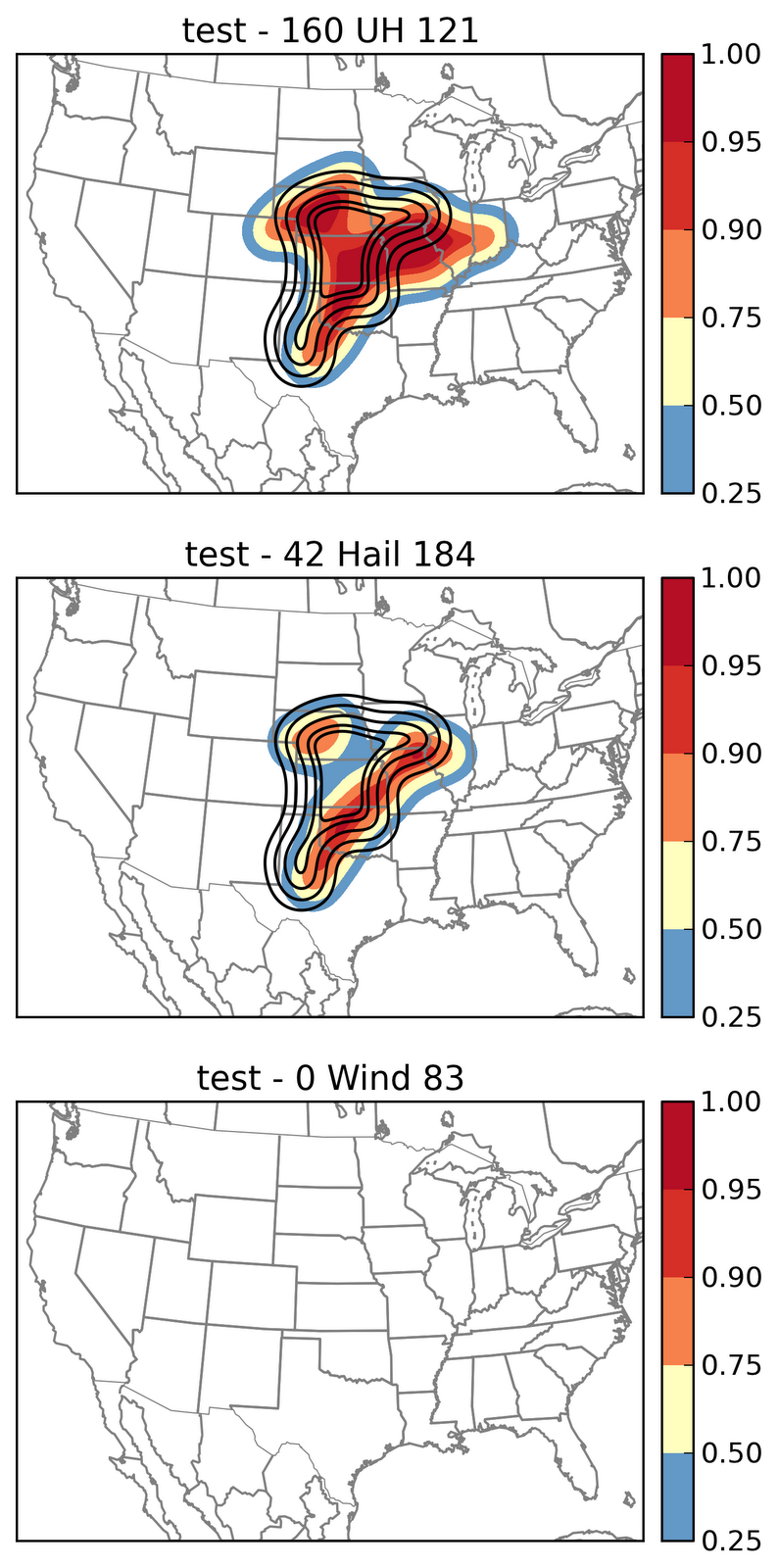
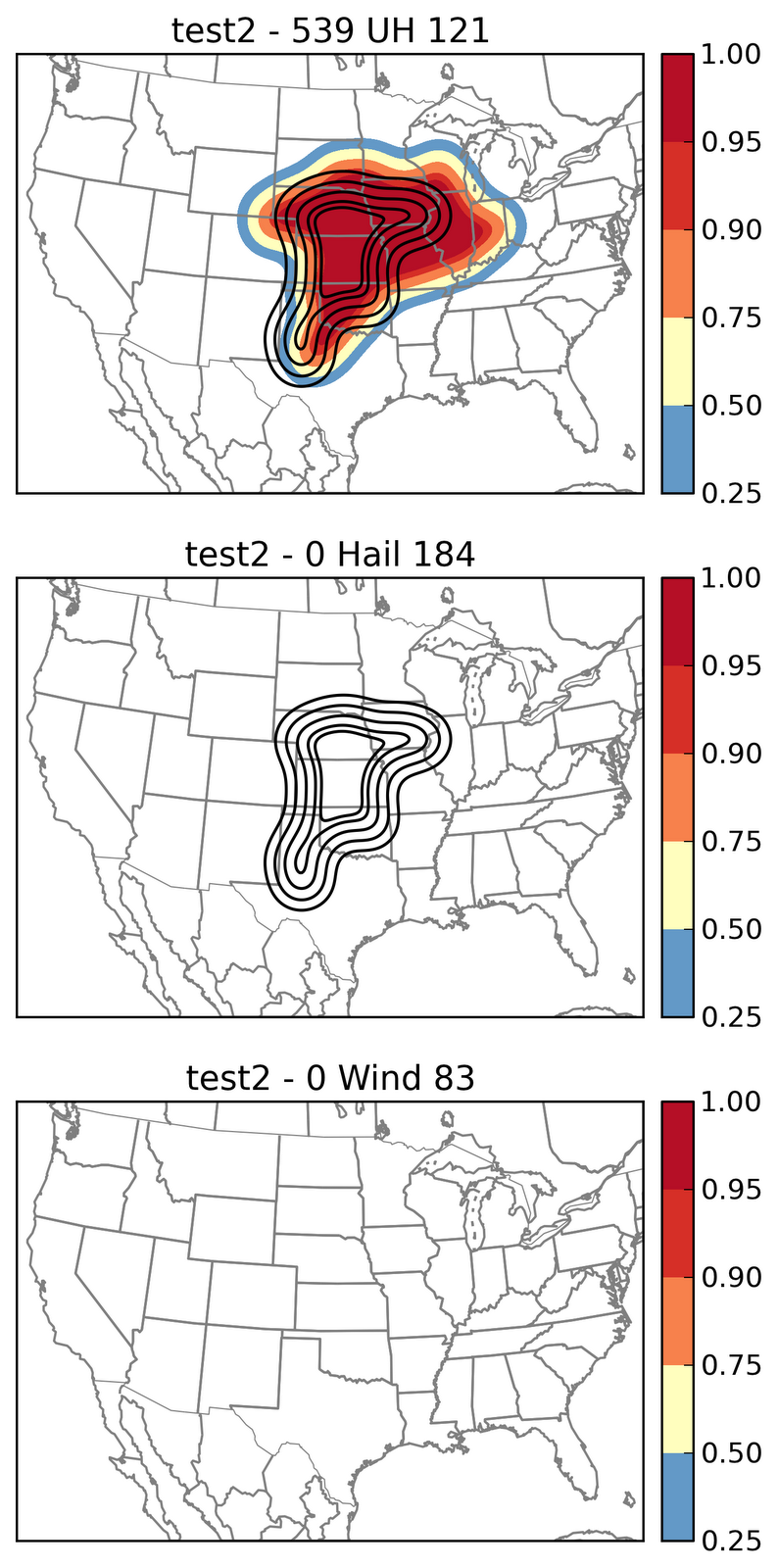
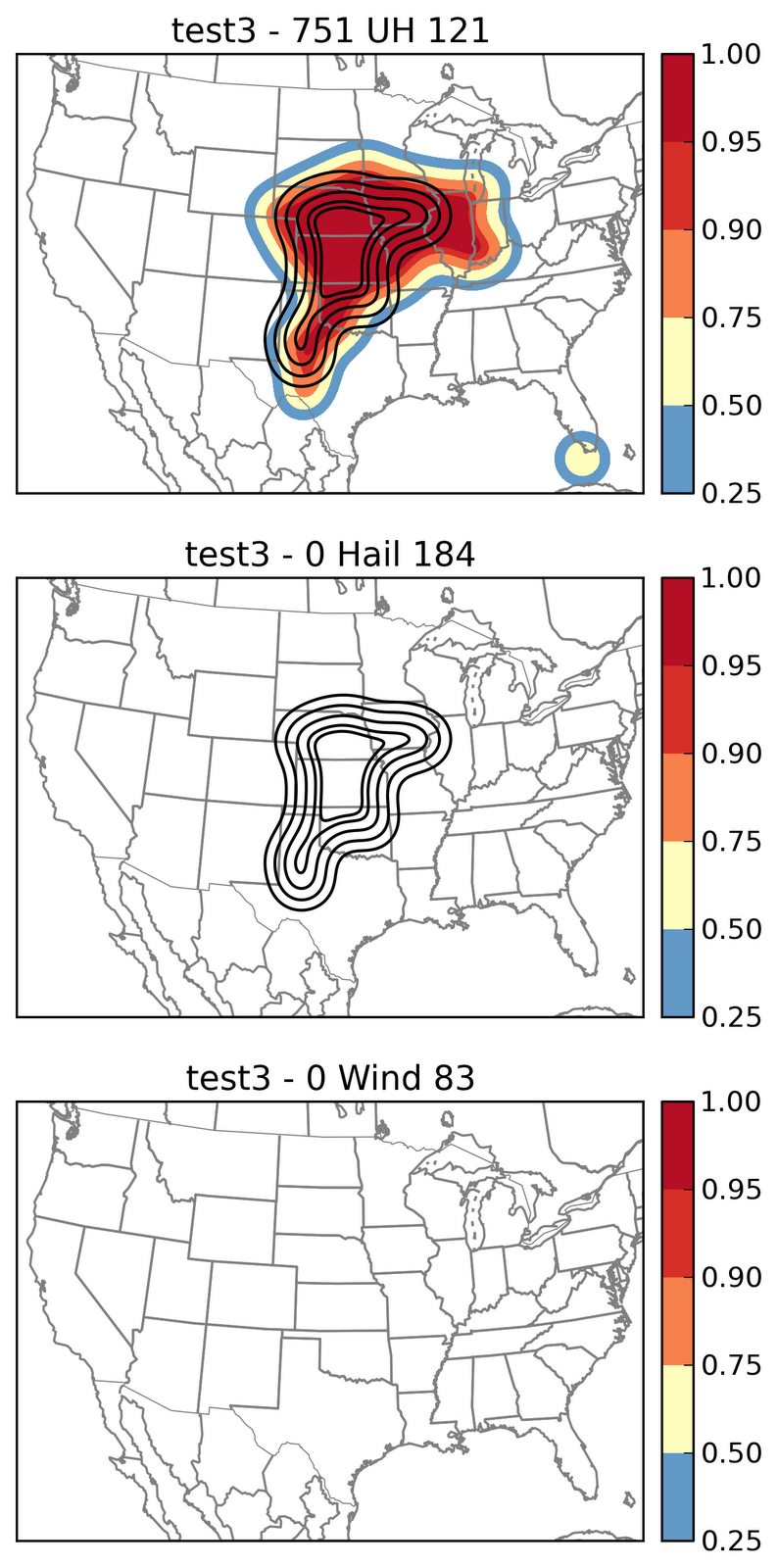
I am really behind on the blog posts. Last week had some challenges especially for severe storms down in south Texas. We have had a few days where the cutoff lows have been approaching south Texas providing sufficient vertical shear and ample moisture and instability. The setup was favorable but our non-met limitation was the border with Mexico. We don’t have severe storm reports in Mexico nor do we have radar coverage. Forecasting near a border like this also imposes a spatial specificity problem. In most cases there is room for error, room for uncertainty especially with making longer (16 hr) spatial forecasts of severe weather. On one particular day the ensemble probabilities were split: 1 ensemble in the US with extension into Mexico, 1 ensemble in Mexico with extension into the US, and another further northwest split across the two unevenly into the US.
So the challenge quickly becomes all about specificity … where do you put the highest probabilities and where are the uncertainties large (i.e. which side of the border). The evolution of convection quickly comes into question also since as you anticipate where the most reports might be (where will storms be when they are in the most favorable environment), you have to also account for if/when storms will grow upscale, how fast that system will move and if it will also be favorable to generate severe weather.
We have discussed this in previous experiments as such: “Can we reliably and accurately draw what the radar will look like in 1, 3, 6, 12, etc hours?”. This aspect in particular is what makes high-resolution guidance valuable. It is precisely a tool that offers what the radar will look like. Furthermore, an ensemble of such guidance offers a whole set of “what if” scenarios. The idea is to cover the phase space so that the ensemble has a higher chance of depicting observations. This is why taking the ensemble mean tends to be better (for some variables) than any individual member of an ensemble.
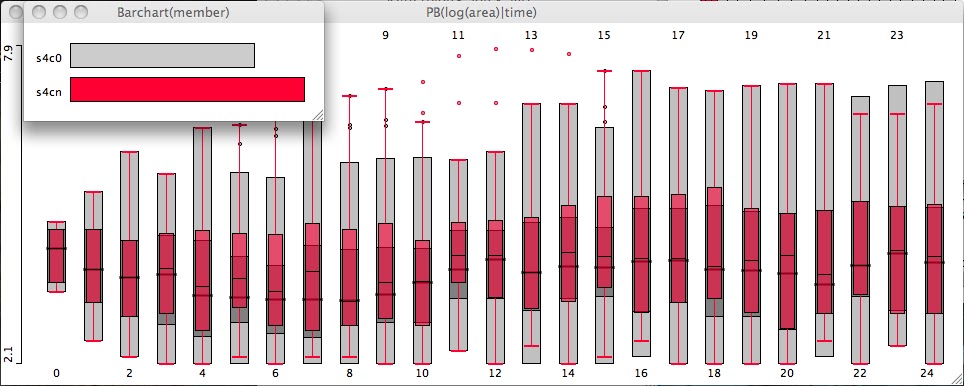
Utilizing all these members of an ensemble can become overwhelming. In order to cope with this onslaught (especially when you 3 ensembles with 27 total members), we create so-called spaghetti diagrams. These typically involve proxy variables for severe storms. By proxy variables I mean model output that can be correlated with the severe phenomenon we are forecasting for. This year we have been looking at simulated Reflectivity, Hourly maximum (HM) storm updrafts, HM updraft helicity, and HM wind speed. Further, given the number of ensembles, we have so-called “buffet diagrams” where each ensemble is color coded but now depicts each and every member. We have also focused heavily on probabilities for each of the periods we have been forecasting for.
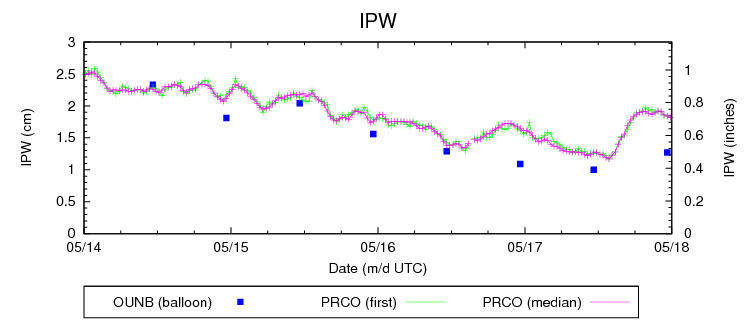
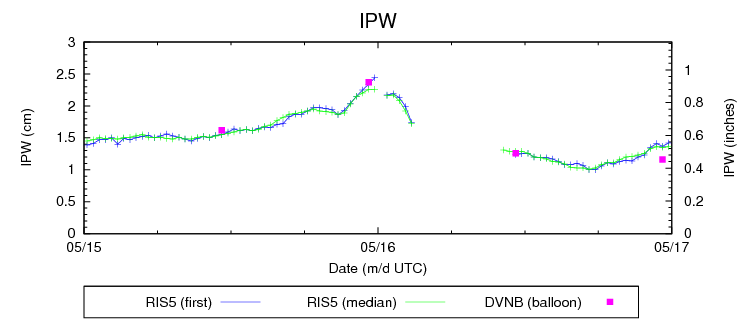
In this case all the probabilities are somewhat uncalibrated. Put another way the exact value of the probabilities do not corresponding directly to what we are forecasting for nor have we incorporated how to map them from model world to the real world. In one instance we do have calibrated ensemble guidance but not for the 2 other ensembles. It turns out you need a long data set to perform calibration for rare event forecasting like severe weather.
Lets come back to the forecasts. Given that each ensemble had a different solution it was time to examine if we could discount any of them given what we thought was a likely scenario. We decided to remove one of the ensembles from consideration. The factors that led to this decision were a somewhat displaced area of convection that did not match observations prior to forecast time, and a similar enough evolution of convection. It was decided to put some probabilities in the big bend area of Texas to account for early and ongoing convection. This was a relatively decent decision as it turned out.
This process took about 2 hours and we didn’t really dig into the details of any individual model with complete understanding. Such are the operational time constraints. there was much discussion on this day about evolution. Part of the evolution was the upscale growth (which occurred) but also whether that convection produced any severe reports. Since the MCS that formed was almost entirely in Mexico, we won’t know whether severe weather was produced. Just another day in the HWT.