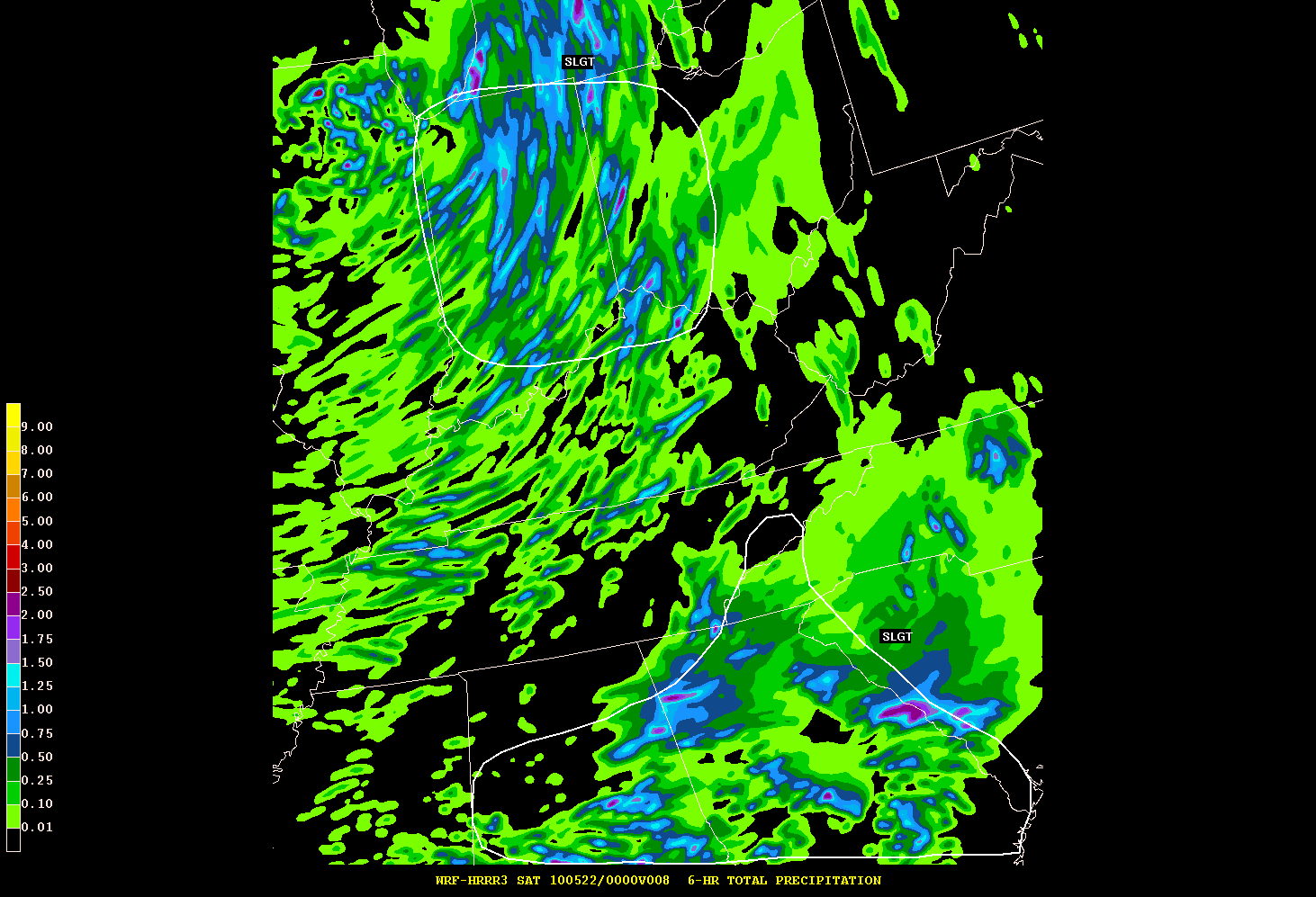
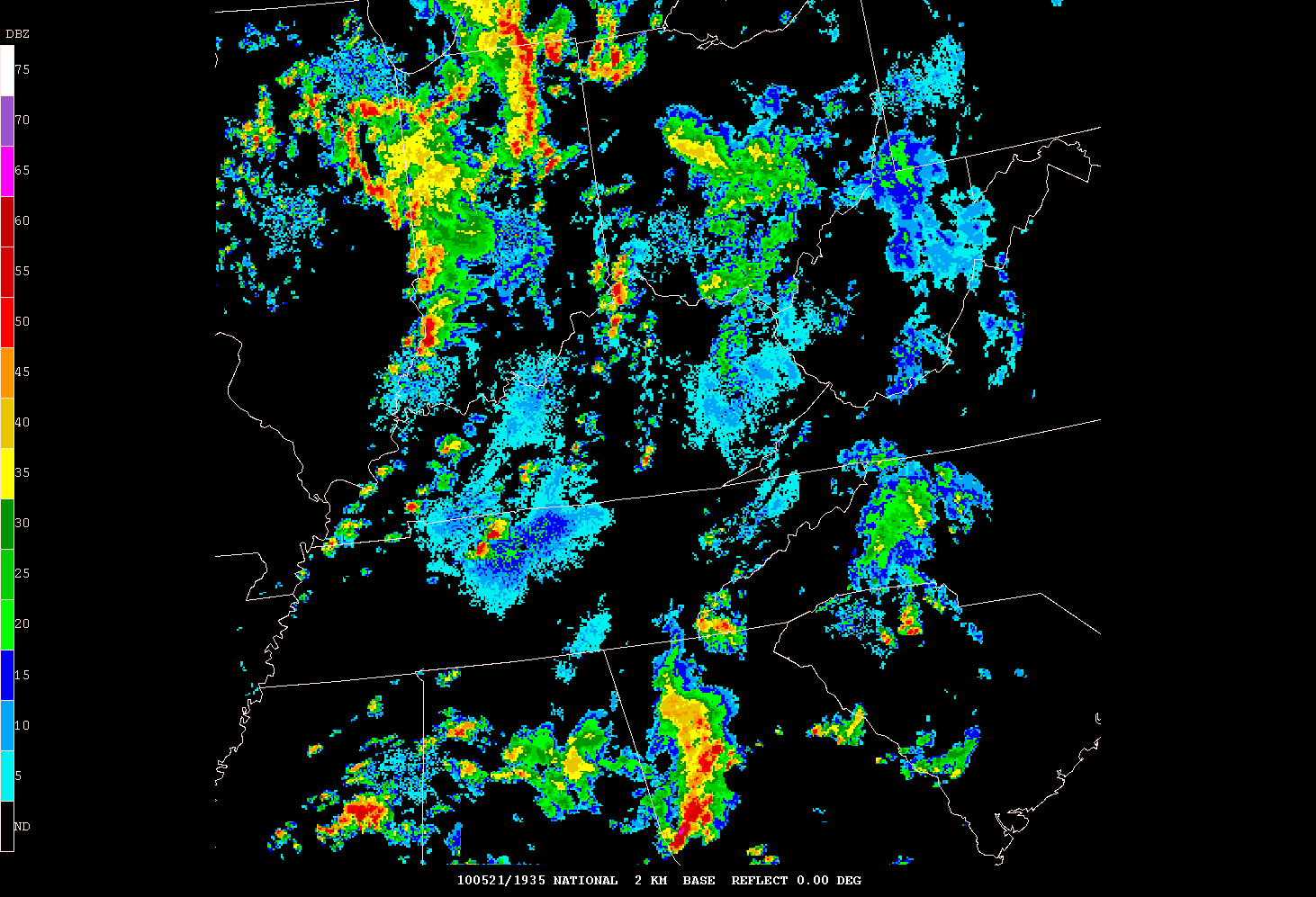
We had many discussions over the last two days. One was regarding CI definitions. Of the variety of opinions we heard, a storm was defined by:
1. Whether lightning occurred,
2. a coherent, continuous thunderstorm that eventually reached a significant low level reflectivity threshold (40-45 dBz) within 30 minutes,
3. any combination of 1 or 2, which also produced severe weather (e.g. it was just a storm, but a severe storm)
These variations on the theme are exactly what we were considering for the experiment, the experimental algorithms from the model, and the forecast verification we had played with prior to the experiment.
Another conversation involved what forecasters would use from the experimental suite of variables. The variables would need to be robust, easy to interpret (e.g. quick to interpret and understand), and clear. This is a tough sell from the research side of things, but it is totally understandable from a forecaster perspective. Forecasters have limited time in an environment of data overload in which to extract (or mine) information from the various models. They have very specific goals too, from nowcasting (e.g. 1-2 hours; especially on days like today where models miss a significant component of what is currently happening), to forecasting (6-24 hours), to long lead forecasting 1-8 days.
We also spent some time discussing the Tuesday short wave trough in terms of satellite data and radiosonde data. I argued that many people believe that satellite data and its assimilation is much more important now (Data volume, coverage, and quality control) than radiosondes. It was mentioned that radiosondes are very important on the mesoscale especially in the 0-24 hour possibly 48 hour forecasts. Still more opinions were expressed that some forecasters have questioned the need for twice a day soundings. Opinions in the HWT ranged from soundings are important, to soundings should be launched more often, to sounding should be launched more often at different times. It is plausible that some of our NWP difficulty may be due to launching soundings at transition times of the boundary layer.
I am of the opinion that if model suites are launched 4 times per day that soundings should be launched at least 4 times per day, especially now where cycling data assimilation is common practice. This would return our field to the 1950’s era where 4 times per day soundings were launched at 3,9, 15, and 21 UTC.
Lastly, we discussed the issue of what happens when a portion of the forecast domain is totally out to lunch? Like today where the NM convection was not represented. I think I will talk about that tomorrow once we verify our forecast in the OK area from today. Stay Tuned.