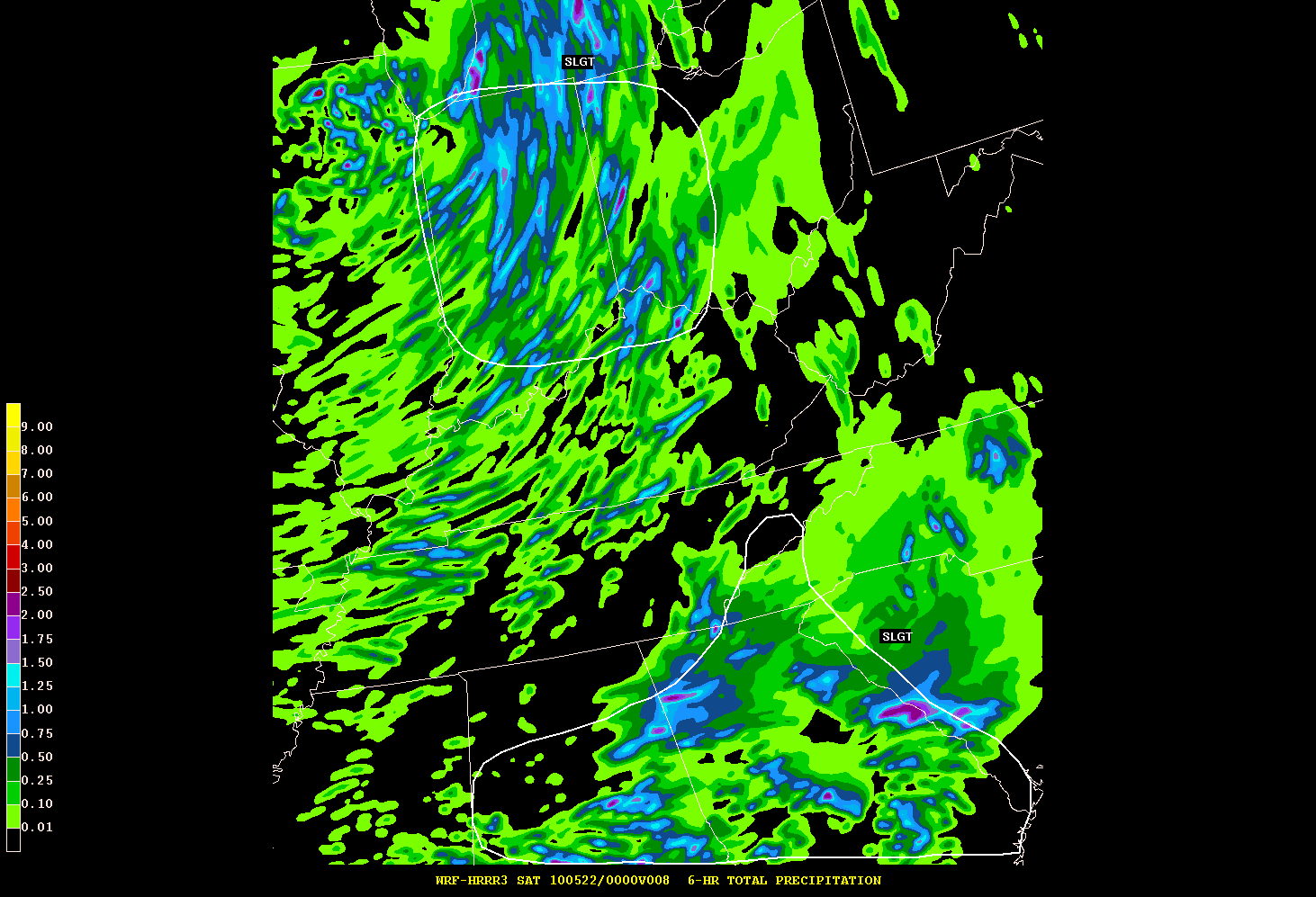
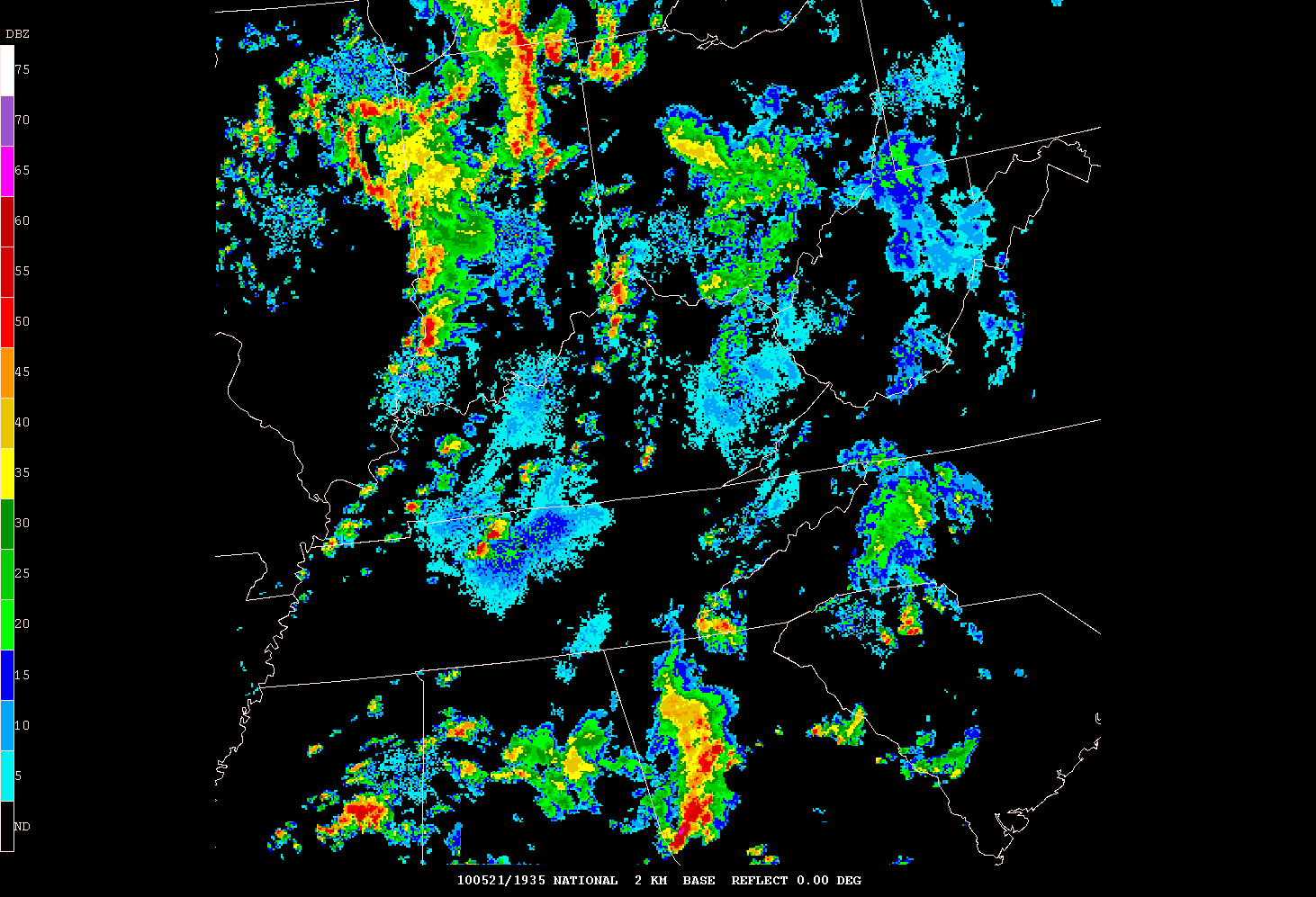
As others have mentioned, I want to thank the SPC and NSSL for coordinating the program once again this year. As a first year participant, I found the experience both challenging and rewarding. Although the overall magnitude/coverage of convective weather continued to be generally below normal – there were still plenty of forecast challenges to keep us busy throughout the week.
Now for some observations (mainly subjective) about a few of the issues we encountered:
1. Having completed a verification project on an early version of the MM5 (6KM horizontal grid spacing) back in the late 1990s, it was interesting to see the current evolution of mesoscale modeling.While there have been many changes/improvements (e.g. microphysics schemes, PBL schemes, radar assimilation, etc) it was evident to me that many of the same problems we encountered (sensitivity to initial conditions, sensitivity to model physics, parameterization of features, upscale growth, etc) still haunt this generation of mesoscale models.
2. With the increase in computer power, we are now able to run models with a horizontal grid resolution of 1km over a large domain in an operational setting!However, examining the 1km output did not seem to add much (if any) value over 4km models – especially considering the extra computational expense.
3. All of the high resolution models still appear to struggle when the synoptic scale forcing is weak.In other words, modeling convective evolution dominated by cold pool propagation remains extremely challenging.
4. The output from the high resolution models remains strongly correlated to that of the parent model used to initialize. Furthermore, if you don’t have the synoptic scale conditions reasonably well forecast, you have little hope in modeling the mesoscale with any accuracy.
5. Not surprising, each model cycle tended to produce a wide variety of solutions (especially during weak forcing regimes) – with seemingly little continuity amongst individual deterministic members (even with the same ICs), or from run to run. Sensitivity to ICs and the lack of spatial and temporal observations on the mesoscale remains a daunting issue!
Even with some of these issues, on most days the high resolution models still provided valuable guidance to forecasters – most notably regarding storm initiation, storm mode, and overall storm coverage.Although the location/timing of features may not be exactly correct, seeing the overall “character of the convection” can still be of great utility to forecasters especially considering they are not available in the current suite of operational models (i.e. NAM/GFS).
From a field office perspective – one of the big challenges I see in the future is how to best incorporate high resolution model guidance into the “forecast funnel.” Being that many forecasters already feel we are at (or even past!) the point of data overload, they need proof that these models can be of utility in the forecast process. Moreover, I believe that on an average day, most forecasters can/will devote at most 30-60 min to interrogate this guidance. Is this sufficient time? During the experiment we were devoting a few hours to evaluating the models – and I still felt we were only scratching the surface.
Next, what is the best method to view the data? A single deterministic run? Multiple deterministic runs? Probabalistic guidance from storm scale ensembles? Model post products (i.e. surrogate severe)? Some combination of the above? In addition, what fields give forecasters the most bang for the buck? Simulated reflectivity, divergence, winds, UH, updraft/downdraft strength? Obviously many of these questions have yet to be answered, however what is clear to me is that significant training is going to be required regarding both what to view, and how to view it.
In terms of verification, the object based methodology that DTC is developing is an interesting concept. Although still in its infancy, I like the idea and do see some definite utility. However, as we noted during the evaluation, it still appears as though this methodology may be best suited for a “case study” approach rather than an aggregate (i.e. seasonal) evaluation (at least at this point).
As echoed by others, it was a privilege to be a participant in this year’s program and I would jump at the opportunity to attend in future years. In my humble opinion, I think the mesoscale models have proved long ago that they do have utility in the forecast process – if used in the proper context. There are obvious challenges to embark upon in the years to come, and I look forward to seeing the continued evolution of techniques/technology in future years.