

Verification is a huge part of the Spring Forecasting Experiment. Each day, we make multiple forecasts on different time scales (this year ranging from daylong outlooks to hourly probabilistic forecasts), and the first activity participants undertake on Tuesday-Friday is an evaluation of the previous day’s forecasts. Additionally, in the afternoon, participants evaluate numerical guidance, by comparing model output to observations.
Selecting how to use observations for verifying some of the more nebulous aspects of severe convective weather is one of the challenges of designing the SFE. With some fields, it is easy enough to compare the simulated with the observed – take reflectivity, for example:
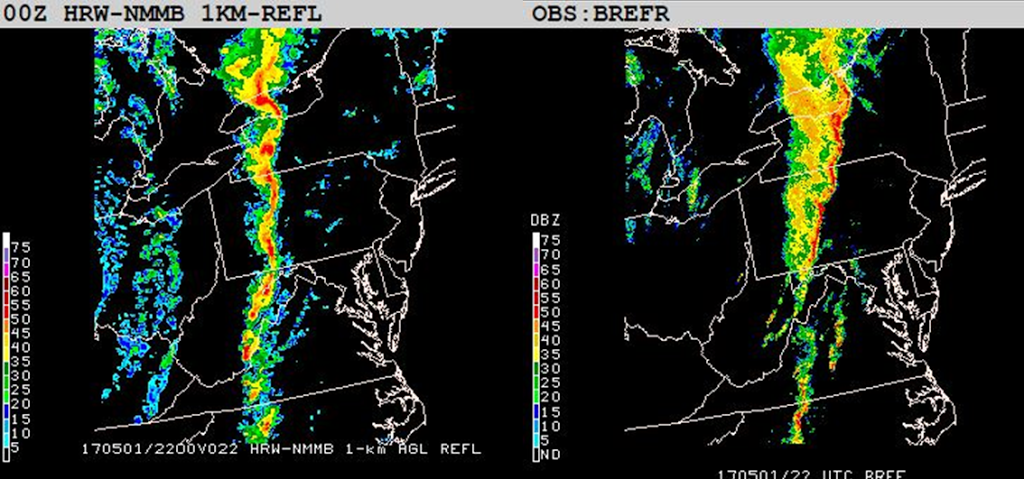
It’s easy to evaluate the reflectivity fields because it’s a 1-to-1 comparison. However, when verifying severe convective hazards, the process becomes much trickier. For storm-scale parameters such as updraft helicity, we often don’t have a direct observation. For other hazards, such as hail size and tornado occurrence, the verification is reliant on human observation of the event – and the subsequent reporting of the event. These Local Storm Reports (LSRs) are dependent on population, and often change quickly in the first few days following an event as storm survey teams evaluate the damage caused by the storms.
Using LSRs for direct evaluation also works best for binary fields – for example, having multiple swaths of updraft helicity in the vicinity of several reports typically indicates a good forecast. But probabilistic forecast issuance is a huge part of the SFE. For example, here was the Innovation Desk’s full-period forecast for 3 May 2017, with the reports plotted over it:
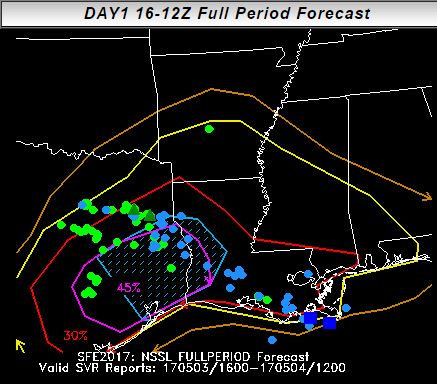
While the reports fall within the forecast area, it’s hard to determine how high the probabilities should be in the areas of densest reports. For evaluating these forecasts, we use “practically perfect” forecasts, which is a method developed by Hitchens et al. (2013) to create a forecast resembling what a forecaster would make with perfect knowledge of the reports beforehand. On 3 May 2017, the practically perfect forecast looks like this:
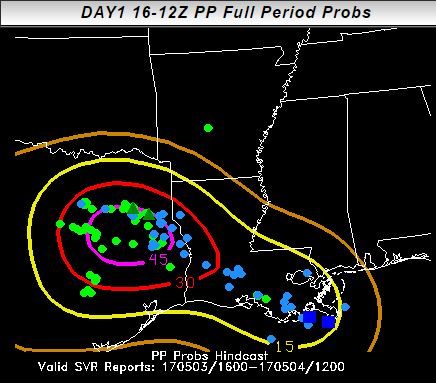
While there are differences in the area covered, most notably in Mississippi, the magnitude of the forecast was approximately correct. On some days, it’s possible to issue a better forecast than the “practically perfect” forecast (hence the “practically”)! For this day, a better than practically perfect forecast would have reduced the 5% and 15% across central Texas, where the front had already passed.
An interesting discussion was had by participants this week, as to how best verify hail forecasts. Currently, we evaluate hail swaths produced by the NWP with observed hail swaths according to the MRMS Maximum Estimated Size of Hail (MESH) algorithm. Example forecasts given by the HAILCAST method (Adams-Selin and Ziegler 2016) and a method based on updraft strength compared to MESH observations are shown below:
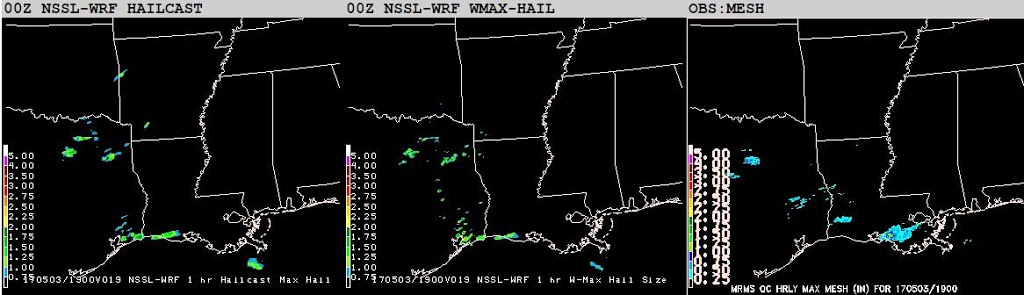
Both of these methods are implemented in the NSSL-WRF, which was producing storms in northeastern Texas. Hail did not occur here in the observations at this time. Since the most obvious error (the “overforecast” of hail in northeastern TX) is linked to the underlying NWP rather than the hail size forecast methods, the leader of the evaluation has to make sure to point out that the displacement is not relevant to the hail size forecasts. Rather, participants should focus on the hail sizes produced by the storms in each model forecast and the hail sizes produced by similar storms in the general vicinity (such as the storms in southern LA). If there is a large enough error in where the underlying model places storms, a more useful evaluation compares the methods of hail size forecast generation to one another more so than to the observations.
Future experiments may try to clarify this evaluation by producing 24-h swaths of hail from both the observed MESH and the forecasts. That way, if the models have a timing error in storms, or a small placement error, it will not detract from the true focus of the evaluation. Other visualizations of hail size forecasts may be useful in future experiments as well. For example, distributions of hail sizes from the forecasts and the observations could be displayed beneath the maps, so that participants could see not only where the most intense hail is being produced by each method, but also how well the overall distribution of sizes compares between the methods irrespective of spatial location. As the SFE evolves, so to do the verification efforts, trying to display the most useful information to participants and garner useful feedback for model developers to improve their guidance.